Une nouvelle année s'éveille, c'est donc le moment annuel d'exhumer cette relique du passé qu'est ce blog afin de le garnir d'un article tout neuf (avant de le ré-enterrer pour les 364 prochains jours). Le projet est toujours le même : savoir ce qu'il faut penser de l'année à venir en regardant uniquement ses propriétés mathématiques. L'outil de référence est toujours l'OIES, et on peut dire que...
L'année 2024 sera vraiment bonne ! Bien sûr, pas au niveau inégalable de 2016, mais on est sur une bonne année à venir.
Diagramme en barres automnal du nombre de propriétés référencée par l'OEIS pour chaque année depuis 2013 et 2023
Le grand nombre de propriétés de 2024 peut sembler étonnant au premier abord, puisque sa décomposition en facteurs premiers (2024 = 2×2×2×11×23) contient plein de petits facteurs premiers différents, ce qui limite les propriétés liées aux nombres premiers. Le secret de 2024, c'est que c'est (entre autres) un nombre qui apparait dans le triangle de Pascal, ce qui lui donne plein de propriétés différentes liées aux coefficients binomiaux. Bref. passons en revue quelques propriétés un peu intéressantes :
2024 est un nombre tétraédrique [A000292] Commençons par la plus importante des propriétés du nombre 2024 : il peut se représenter sous la forme d'un tétraèdre à 22 étages !
2024 balles représentées sous la forme d'un tétraèdre (pyramide dont toutes les faces sont des triangles équilatéraux)
Si on regarde cette pyramide de balles couche par couche, on peut voir qu'elle est formée de couches successives de balles disposées en triangles. Un nombre tétraédrique, c'est donc une somme de nombre triangulaires. Notons alors :
t(n) = 1 + 2 + 3 + ... + n le n-ième nombre triangulaire, et
T(N) = 1 + 3 + 6 + ... + t(N) le N-ième nombre tétraédrique
On a donc :
Or, il est bien connu que t(n) = 1 + 2 + 3 + ... + n = n(n+1)/2 (je vous renvoie à mon article sur 2016 si vous en voulez une petite démonstration), donc :
On réutilise alors la formule de la somme des entiers (Ʃn = N(N+1)/2) et celle, un peu moins connue, de la somme des carrés (Ʃn² = N(N+1)(2N+1)/6), d'où :
Et en simplifiant un peu, après factorisation :
Bref, on a une jolie formule pour le N-ième nombre tétraédrique, ce qui permet d'en déduire que le 22e est bien T(22) = 22×23×24/6 = 2024
-
Une autre façon de visualiser les nombres tétraédrique, c'est d'observer un triangle de Pascal :
Le triangle de Pascal : on place un 1 dans la case la plus haute, et on complète le reste en utilisant sa propriété caractéristique : chaque case est égal à la somme des deux cases juste au dessus.
Dans un triangle de Pascal, on observe facilement que la première diagonale (montante) est constituée uniquement de 1, et la deuxième est constitué par les entiers consécutifs. Un peu moins évident, la troisième diagonale, en vert, donne la suite des nombres triangulaires. En effet, puisque chaque nombre est la somme des deux nombres au-dessus, le troisième nombre de la n-ième ligne est la somme du deuxième nombre de la ligne précédente (qui est n) et du troisième (qui est le nombre triangulaire précédent). Avec le même raisonnement, on peut voir que la quatrième diagonale, en rouge, donne la suite des nombres tétraédriques, puisqu'on peut voir qu'elle correspond aux sommes des nombres triangulaires.
On peut alors en conclure que le N-ième nombre tétraédrique peut s'écrire à l'aide d'un coefficient binomial:
On en déduit alors que 2024, c'est 3 parmi 24. Il y a donc 2024 façons différentes de choisir 3 heures dans une journée.
Les diagrammes de Farey [A358882] Prenez toutes les droites du plan dont l'équation cartésienne est de la forme ux + vy = w, avec u, v, w entiers tels que |u| ≤ N et |v| ≤ N. Conservez de toutes ces droites uniquement les egments qui passent par le carré unité (=[0,1]²). Vous obtiendrez alors ce que l'on appelle le N-ième diagramme de Farey :
Les 4 premiers diagrammes de Farey, avec respectivement N=1, 2, 3 et 4.
Si vous êtes motivés à compter le nombre de zones, vous constaterez avec étonnement que le 4eme diagramme délimite 1568 triangles et 456 quadrilatères, soit un total de 2024 polygones.
Dans le même ordre d'idée, il y a aussi les figures obtenues en traçant toutes les droites passant par 4N points disposés régulièrement sur le périmètre d'un carré [A345459]. Pour N=4, on obtient la figure ci-dessous, qui délimite exactement 2024 polygones (1120 triangles, 824 quadrilatères et 80 pentagones)
Cliquez ici pour voir la même figure, mais en plus grand, en plus complet et en plus coloré.
Mais aussi...
Il y a 2024 façons de décomposer le nombre 24 en sommes de carrés, en tenant compte de l'ordre (comme par exemple 24 = 1² + 2² + 3²+3²+1²). [A006456]
Sur un échiquier 12×12, il y a 2024 façons différentes de déplacer un fou [A002492]
2024 est un nombre dodécaédrique, mais j'ai vraiment pas le courage de le dessiner maintenant [A006566]
2024 et 2295 sont des nombres "fiancés" (ou "quasi-amicaux"), car la somme de leurs diviseurs est dans les deux cas égale à 4320, ce qui est égal à 2024+2295+1 [A005276]
Bonjour à tous. Nous sommes à l’aube d’une nouvelle année, il est donc l’heure pour moi de réouvrir ce qui me sert annuellement de blog afin de répondre à cette sempiternelle question : l’année qui vient sera-t-elle intéressante ?
Toujours la même boule de cristal pour répondre à cette question : l’OEIS. C’est l’encyclopédie qui répertorie un nombre bien trop grand de suites de nombres entiers, et qui permet de mesurer de manière ultra-rigoureuse et parfaitement scientifique la qualité d’un nombre entier. Plus le nombre apparait dans l’encyclopédie, plus il sera intéressant. On peut alors en extrapoler la qualité de l’année qui vient, ce qui me permet donc d’annoncer que…
2023 sera “mouais”... Pas inintéressante, mais faut pas trop en attendre non plus
Nombre de propriétés recensées par l'OEIS pour chaque année depuis 2012
Le nombre 2023 a, à l’heure où j’écris ces lignes, 238 propriétés cataloguées. Creusons un petit peu plus malgré tout pour en trouver celles qui ressortent du lot.
En l’an 67, l’armée de l’empereur Vespasien organise le siège de la forteresse de Iotapata. L’historien Flavius Josèphe est sur place et fait partie des assiégés. Avec 40 de ses soldats, ils se réfugient dans une cave. On va les numérotés de 1 à 41, et on dira que Josèphe est lui aussi un soldat pour simplifier l’exposé. Plutôt que de se rendre à l’ennemi, ils décident de se donner eux-même la mort. Ils s’en remettent alors au quasi-hasard pour décider de l’ordre. Plus précisément, commencer par choisir au hasard un premier soldat. Disons qu’il s’agit du n°40, vous simplifier les comptes.
Qui va survivre ?
À partir de celui-ci, il est convenu que le premier à mourir sera le troisième à sa gauche, puis le suivant sera le troisième à gauche de celui qui vient de mourir, et ainsi de suite. La question qui se pose alors pour Josephe, qui n’a aucune envie de se suicider, c’est de savoir quelle sera la position de dernier à rester debout.
Le plus simple pour avoir la réponse à cette question, c’est simplement de lancer la simulation.
Dans un premier temps, tous les soldats qui occupent une position multiple de 3 seront tués.
Les 13 premiers malheureux à périr seront les porteur d'un numéro multiple de 3.
Après le premier tour, on poursuit le processus, avec le numéro 1, puis 5, puis le 10, etc. On peut alors vérifier que le dernier emplacement libre sera le 31.
Il fallait donc se placer en position 31. Félicitations au survivant !
Pour un nombre quelconque de soldats, ce nombre peut se calculer avec une formule récursive. En notant J(n) l’emplacement du dernier soldat debout pour n soldats présents, on peut montrer que l’on a :
J(1) = 1
et J(n) = J(n-1) + 3 modulo n
Il a cependant fallu attendre 1997 pour découvrir une formule qui permet de calculer directement ce résultat. La formule est parfaitement horrible, et cache surtout l’utilisation d’une constante α qui elle doit être calculée au préalable. Ce n’est pas vraiment ce que l'on appelle un formule pratique.
En référence à ce problème, Stanislas Ulam et ses amis inventent dans les années 50 le crible de Josèphe. On commence donc par prendre tous les entiers naturels :
Les nombres restants sont appelés des nombres chanceux de Josèphe, et, en 50e position, le nombre 2023 !
Il existe 2023 pavage d’un carré 4x4 par des carrés unité et des triominos L [A220061] Un triomino est un polygone formé à partir de trois carrés accolés. Il n’en existe que deux : le triomino L et le triomino I.
Les deux seuls triominos. Voici L et I.
Une des propriétés pratique du triomino L, c'est le théorème de Golomb. Il est toujours possible de paver à l'aide de triominos L un échiquier 8×8 auquel on a retiré un carré. Pour montrer cela, il faut commencer par observer qu’un triomino L peut être pavé par 4 triomino L deux fois plus petits.
Prenons maintenant un échiquier, auquel on a retiré un case.
L'idée est de procéder par récurrence. On va découper l'échiquier 8×8 en quatre carrés 4×4. L'un de ces quatre carrés contient alors la case retirée, pendant que les trois autres sont intacts. On peut alors recouvrir ces trois grands carrés par un grand triomino L. En remplaçant ce grand triomino L par quatre plus petits, et en répétant l'opération, on peut alors paver la grande zone en L par 16 petits triominos L.
Étape 1 : on partage l'échiquier en 4 carérs identiques Étape 2 : on pose un grand triomino L sur les trois emplacements sans la case manquante
Étape 3 : on découpe ce triomino L en 4 triominos L plus petits Étape 4 :on découpe chacun des triominos de l'étape précédente en 4 triominos L plus petits
Il reste alors un carré 4×4 avec une case manquante. On peut reprendre toutes les opérations précédentes sur ce plus petit carré. En recommençant suffisamment de fois, on va finir par intégralement recouvrir notre échiquier par les triominos L.
Étape 5 : on reprend l'étape 2 sur le quadrant laissé de côté à l'étape 1 Étape finale : on savoure ce pavage de l'échiquier
Le processus se généralise, ce qui permet d’affirmer que n’importe quel échiquier de taille 2n×2nauquel une case est retirée peut se faire paver par des triominos L.
Et puisque l'on parle de petits carrés et de triominos L, on peut se demander combien il existe de façons différentes de paver un carré 4×4 avec ces deux types de pavés. La réponse est : 2023.
Quelques exemples parmi les 2023 possibles
2023 est un nombre heptagonal concentrique [A195041].
La preuve en image qui pique les yeux :
2023 points disposés en heptagone. Ce n'était pas nécéssaire, mais je l'ai fait.
Cette horrible image permet de mettre en image que 2023 = 7×17². Il s'agit en effet d'heptagones concentriques qui comptent respectivement 7×1, 7×3, 7×5, …, 7×37 points. Or, la somme 1+3+5+...+n des n premiers nombres impairs est égal à n².
On a alors 1+3+5+...+37=17², et donc bien un total de 7×17² points.
Et sinon…
En anglais, le nombre 2023 s’écrit uniquement avec des mots qui commencent par la même lettre (Two thousand twenty-three) [A146755]
Quand on divise 7^7 (=823543) par 7! (=5040), il reste 2023. [A063709]
2023 est un nombre de la forme (3n²+17n)/2, car 2023 = (3×34² + 17×34)/2. Oui, ce n’est pas une propriété très excitante.[A140674]
Si on joue aux fléchettes avec 34 flèches, le plus petit score qu’il est impossible de faire sur une cible réglementaire est 2023. Cette propriété n’a rien à voir avec la propriété précédente. [A241746].
On peut écrire 2023 nombres différents de la forme x^y, avec x et y compris entre 1 et 48.[A126255]
Nous sommes le 1er janvier. C'est donc le début d'une nouvelle année. C'est donc aujourd'hui que je publie ma note annuelle pour faire comme si j'étais encore un vrai blogueur.
Bref : à quoi peut-on s'attendre pour cette année 2022 ?
Pour le savoir, il n'y a qu'une seule façon de procéder : lire dans les arcanes de l'OEIS, l'encyclopédie en ligne des suites entières. Plus un nombre est présent dans les suites de cette enyclopédie de référence, plus l'année correspondante sera intéressante. C'est scientifique.
Après une année 2016 incroyable, une année 2017 passionnante, des années 2018 et 2019 pas très intéressante et des années 2020 et 2021 étonnantes, il est l'heure de vous annoncer que...
l'année 2022 sera passable
Nombre de propriétés recensées par l'OEIS pour chaque année depuis 2012, avec un motif nuage du plus bel effet
Désolé de vous l'annoncer comme ça, mais ça va mieux en le disant. Avec seulement 214 propriétés recencées dans l'OEIS, le nombre 2022 est dans la moyenne basse de ces dernières années. Mais on va tout de même investiguer, à la recherche d'une petite pétite.
2022 est le premier terme d'une suite de nombres de Harshad [A141769] On dit qu'un nombre entier est un nombre de Harshad [du sanskrit "harṣa" ("joie") et "da" ("qui donne")] lorsqu'il est divisible par la somme de ses chiffres. C'est bien le cas du nombre 2022, puisqu'il est divisible par la somme 2+2+0+2 = 6.
Il se trouve cependant que 2023, 2024 et 2025 sont aussi des nombres de Harshad, ce qui rend la propriété pour 2022 un peu moins satisfaisante : 2023 est divisible par 7, 2024 est divisible par 8 et 2025 est divisible par 9. Mais puisque tous les successeurs de 2022 sont aussi des nombres de Harsahd, ça rend 2022 le premier terme d'une suite de 4 nombres de Harshad, et ça, c'est déjà un peu plus intéressant.
Se pose alors la question : existe-t-il des suites de nombre consécutifs de Harshad qui soient aussi longues que celle de 2022, voire plus longue ? O va mettre de côté la suite (1, 2, 3, 4, 5, 6, 7, 8, 9, 10) qui est une suite de 10 nombres de Harshad consécutifs, parce qu'elle n'est pas du tout incroyable, et on va se concentrer sur les suivantes :
510, 511, 512, 513 : longueur 4
1014, 1015, 1016, 1017 : longueur 4
2022, 2023, 2024, 2025 : longueur 4
3030, 3031, 3032, 3033 : longueur 4
Il faudra attendre (131 052, 131 053, 131 054, 131 055, 131 056) pour avoir 5 nombres de Harsahd consécutifs, et (10 000 095, 10 000 096, 10 000 097, 10 000 098, 10 000 099, 10 000 100, 10 000 101) pour en avoir 7. On connait aussi le plus petit entier qui débute une séquence de 14 nombres de Harshad consécutifs : c'est 4201420328711160916072939999999999999999999999999999999999999996. Et on peut même aller plus loin, avec le nombre de Cooper et Kennedy [lien] qui compte 44 363 342 786 chiffres et qui débute une suite de 20 nombres de Harshad consécutifs.
Est-il alors possible de trouver des suites de nombres de Harsahd consécutifs aussi longue que l'on veut ? Eh bien... non ! Le maximum est de 20, et c'est généralisable dans toutes les bases : en base n, il n'existe jamais plus de 2n nombres de Harshad consécutifs [lien]. Vous ne trouverez donc jamais 2022 nombres de harsahd consécutifs (sauf si vous cherchez dans la base 1011, bien entendu).
Aux rotations près, il y a 2022 triangles équilatéraux à coordonnées entières dans un cube de côté 7 [A103501] Prenez la grille carrée de dimension 7×7 ci-dessous. Combien est-il possible d'y tracer de carrés, de façon à ce que les sommets des carrés tombent bien sur les noeuds de la grille ?
Avec un peu d'astuce, vous pourrez démontrer qu'il y en a très exactement 336. On peut même prouver que dans une grille de dimension n×n, on aura n(n+1)²(n+2)/12, mais ce n'est pas l'objet de cet article. La vraie question, c'est combien de triangles équilatéraux est-il possible d'y tracer ?
Trois carrés par les 336 possibles. Mais combien de triangles équilatéraux ?
Pour ce qui est des triangles équlatéraux, on peut démontrer qu'il y en a très exactement... aucun. C'est un résultat que l'on doit au mathématicien Edouard Lucas : il est impossible de trouver un triangle équilatéral pour lequel les trois sommets sont tous sur les mailles d'un réseau carré, même très grand.
On peut trouver des triangles presque équilatéraux, mais aucun qui ne le soit parfaitement. Les deux triangles ci-dessous n'ont pas vraiment trois côtés égaux.
On peut le prouver de façon algébrique, mais il y a une jolie preuve visuelle de ce résultat. Pour cela, supposons qu'il existe quelque part dans un réseau carré un triangle équilatéral (représenté en bleu). À partir de ce triangle, on peut construire, par translation des côtés du triangle, un hexagone (en vert) dont les six sommets sont eux aussi sur le réseau.
Si on suppose que le triangle bleu équilatéral appartient au réseau, alors il en est de même de l'hexagone vert.
À partir de cet hexagone vert, on va construire un nouvel hexagone (en rouge), plus petit et dont les six sommets sont aussi sur le réseau. Pour cela, on va faire effectuer à chaque segment composant l'hexagone une rotation d'un quart de tour. Cette construction permet de s'assurer que ces nouveaux segments (en orange) appartiennent eux aussi au réseau.
Si on suppose que l'hexagone vert appartient au réseau, alors il en est de même de l'hexagone rouge.
À partir de cet hexagone rouge qui appartient au réseau, on peut en construire encore un autre plus petit qui appartient aussi au réseau, et ainsi de suite. On pourrait donc construire un hexagone aussi petit que l'on veut et dont tous les sommets appartiennent au réseau : c'est impossible, car une figure ne pourra jamais être plus petite que la plus petite maille du réseau. L'hypothèse initiale est donc à rejeter : on ne peut pas trouver de triangle équilatéral dans un réseau de carrés.
On peut alors se poser la même question en 3 dimensions : combien existe-t-il de triangles équilatéraux dans un réseau cubique de dimension 7×7×7 ? Contrairement à son équivalent bidimensionnel, ces triangles existent bien. Dans un simple cube unité, on peut d'ailleurs en trouver 8 différents :
Dans un réseau cubique de dimension 1×1×1, on peut trouver 8 triangles équilatéraux.
Dire qu'il y a 8 triangles différents, c'est malgré tout faire semblant de ne pas voir que ces 8 triangles sont identiques, à une rotation près. C'est plus honnête de dire qu'il n'y a qu'un seul.
Ainsi, pour un réseau cubique de dimension 2×2×2, on pourra compter 10 triangles équilatéraux vraiment différents :
On peut placer 10 triangles équilatéraux à coordonnées entières dans un cube 2×2×2, à une rotation près.
Et pour un réseau cubique de dimension 7×7×7, le nombre de triangles équilatéraux s'élève a très exactement... 2022 !
Un triangle possible parmis les 2022 possibles
Il y 2022 arêtes dans ce joli dessin [A341764] On part d'une ellipse (en rouge) deux fois plus large que haute, et on la découpe en 14 secteurs (en noir). On obtient donc 14 points sur cette ellipse (en rouge). On relie alors 2 à 2 par des segments (bleus) chaque de ces 14 points, et l'on obtient ceci :
Je ne sais pas bien si c'est très joli, mais ce que je peux vous affirmer, c'est que cette figure contient 2022 petits segments.
Mais aussi :
2022 est un nombre de 3-Smith : la somme des chiffres de ses diviseurs premiers est égal au triple de la somme de ses chiffres. En effet, 2022 = 2×3×337, et (2)+(3)+(3+3+7) = 18 = 3 × (2+0+2+2). [A104391]
2022 est un "nombre magique" en chimie, ce qui correspond aux numéros atomiques des gaz noble. Il ne faut pas s'attendre cependant à voir de sitôt des atomes à plus de 2000 protons... [A018227]
En anglais, chaque mot de 2022 commence par un T. [A146755]
1209/2022 est une très bonne approximation de γ, la constante d'Euler-Mascheroni [A217767].
Il existe 2022 matrices 3x3 de déterminant 1 dont les coefficients sont 0, 1 ou 2. [A279725]
Incroyable ! J'ai toujours un blog ! Et comme nous sommes à l'aube d'une nouvelle année, il est l'heure de se livrer à la tradition annuelle : consulter les astres de l'OEIS, et révéler ce que les arcanes de la numérologie pourront prédire de l'année qui arrive.
Les prédictions de l'année passée se sont révélées parfaitement exactes, puisque l'année 2020 a comme prévu été "pas mal" (si l'on met bien entendu de côté cette anecdotique histoire de pandémie mondiale). Mais que nous réserve l'année 2021 ? Eh bien, elle sera...
Meilleure que 2020 !
Nombre de propriétés répertoriées par l'OEIS pour chaque année. Conjecture : le nombre de propriétés reflète l'intérêt d'une année.
Avec ses 299 propriétés répertoriées par l'Encyclopédie en ligne des suites entières, le nombre 2021 se révèle être assez riche. Il faut dire que le nombre 2021 a une décomposition en nombres premiers intéressante : 2021 = 43 × 47. Il s'agit donc d'un nombre semipremier, car il est le produit de deux nombres premiers. Mais ces deux nombres premiers ont la riche idée d'être consécutifs, ce qui n'est pas banal. La présence de petits chiffres permet aussi à ce nombre d'avoir des propriétés dans d'autres bases de numération (en particulier, les nombres qui s'écrivent 2021 en base 3 et 4 sont des nombres premier, puisqu'il s'agit de respectivement 61 et 137).
Le polyomino 12-zigzag possède 2021 ceintures [A060641] Un polyomino est un assemblage de carrés unitaires joints par leurs arêtes, à l'image des pièces de Tetris. On dit qu'un polyomino est "ceinturé" lorsqu'il est complètement entouré par des copies de lui-même qui ne se chevauchent pas, et qui ne laissent aucune arête libre. Les rotations sont acceptées, mais pas les images miroirs.
Essayons de ceinturer un L-tétromino, le polyomino constitué de 4 carrés formant la lettre L. Le polyomino A est parfaitement ceinturé par 5 copies de lui-même. La configuration qui entoure le polyomino B n'est pas valide, car l'une des copies est une image miroir. Le polyomino C est lui aussi mal ceinturé : deux copies se superposent, et une arête est laissée libre.
On peut alors se demander le nombre de façons de ceinturer un polyomino donné. Il y a par exemple 13355 façons de ceinturer notre L-tétromino. Il n'y a cependant que 3 façons de ceinturer l'ennéamino ci-dessous, qui est le plus petit des polyomino possédant cette propriété. Saurez-vous retrouver ces trois ceintures ?
Quant au polyomino appelé "12-zigzag", il possède exactement 2021 ceintures.
Un exemple de ceinture parmi les 2021 qui existent.
2021 est un nombre de la forme n² + n + 41 [A202018] Pour n = 44, on a bien n² + n + 41 = 44²+44+41 = 2021. Cette propriété peut sembler particulièrement arbitraire, mais le polynôme n²+n+41 est en fait très intéressant. Pour toutes les valeurs entières de n comprises entre 0 et 39, le polynôme P(n) = n²+n+41 génère un nombre premier :
Au-delà de n=39, certains P(n) seront des nombres premiers (P(42)=1847, P(43)=1933, ...), et d'autres non (P(44)=2021, ...).
Cette propriété s'observe assez bien sur ce que l'on appelle la spirale d'Ulam, attribuée au mathématicien Stanisław Ulam. On raconte qu'il a découvert cette représentation des nombres premiers un peu par hasard, alors qu'il écoutait un exposé très long et très ennuyeux. Sur sa feuille, il a disposé les nombres entiers sous forme d'une spirale, puis il a colorié les nombres premiers.
Au premier abord, il n'y a rien à voir, mais si on pousse le dessin plus loin, on trouve cette spirale d'Ulam.
La spirale d'Ulam. En bleu les nombres premiers, en rouge les nombres premiers de la forme n²+n+41 et en jaune les autres nombres (composés).
Ce que l'on observe d'étonnant dans cette représentation des nombres entiers, c'est la présence de lignes obliques, ce qui traduit un certain ordre dans les nombres premiers. La présence de ces diagonales traduit l'existence de polynômes de degré 2 (a.n²+b.n+c) qui donnent un grand nombre de nombres premiers.Les nombres premiers de la forme n²+n+41 forment des lignes remarquables.
En débutant la spirale en 41 plutôt qu'en 1, les nombres premiers de la forme n²+n+41 ressortent de manière encore bien plus évidente.
Est-il alors possible de trouver un meilleur polynôme P(n), qui donnerait uniquement des nombres premiers quels que soient la valeur de n ? On a par exemple le polynôme
P(n) = 36n²-810n+2753
qui donne des nombres premiers (éventuellement négatifs) pour n compris entre 0 et 44. Mais quoiqu'il arrive, il est impossible de trouver un polynôme à une variable qui ne donnerait que des nombres premiers. Il y a bien un polynôme de degré 26 qui fait exception. Il a 25 variables, et toutes ses valeurs positives sont des nombres premiers. Il ressemble à ceci :
Il y a bien sûr une arnaque, quand on regarde la formule de plus près. le polynôme est de la forme (1-TRUC) × (k+2), où TRUC est une somme d'expressions au carré, donc, positif. Pour que le tout soit positif, il faut donc que TRUC soit égal à zéro, ce qui revient à résoudre 14 équations en même temps. Ce polynôme n'a en fait jamais généré autre chose que des nombres premiers très petits. Tout ça n'a aucun rapport avec 2021, mais je trouve ça tout de même intéressant.
2021 est le nombre de ϕ-partitions de 49 [A283528] Pour expliquer ce qu'est une ϕ-partition, il faut expliquer ce qu'est une partition, et expliquer à quoi correspond ϕ. Commençons par les partitions. Combien y a-t-il de façons d'écrire le nombre 7 sous la forme d'une somme décroissante d'entiers non nuls ? Détaillons :
Il y a donc 15 façons d'écrire 7 sous la forme d'une somme. On dit donc que 7 a 15 partitions. Le nombre 49, quant à lui, possède pas moins de 173525 partitions.
L'indicatrice d'Euler ϕ, maintenant. Combien de nombres entiers inférieurs au nombre 7 sont premiers avec 7 ? Il y en a 6 : 1, 2, 3, 4, 5 et 6 (puisque 7 est un nombre premier, tout entier inférieur est premier avec lui). On dit alors que ϕ(7) = 6. On a de même ϕ(1)=1, ϕ(2)=1, ϕ(3)=2, ϕ(4)=2, ϕ(5)=4 et ϕ(6)=2.
Une ϕ-partition d'un nombre n, c'est alors une partition de n qui reste vraie quand on remplace chaque nombre par son indicatrice d'Euler. Par exemple, la partition 7= 5+1+1 est une ϕ-partition, car ϕ(7) = ϕ(5)+ϕ(1)+ϕ(1). Le nombre 7 possède alors deux autres ϕ-partitions : 7=2+1+1+1+1+1 et 7=3+1+1+1+1. On ne compte par la partition 7=7, qui manque d'intérêt. Ce qui ne manque cependant pas d'intérêt, c'est le nombre 49 qui possède très exactement 2021 ϕ-partitions.
Mais aussi...
2021 est la concaténation de deux nombres entiers consécutifs, comme 1920 ou 2122 [A001704]
Le carré de 2021 est 4084441. Le miroir de 4084441 est lui aussi un carré : 1444804 = 1202². Le nombre 2022 aura aussi cette propriété.[A035123]
Il existe 2021 façons d'écrire 1/7 comme la somme de l'inverse de 4 entiers. Par exemple 1/7 = 1/21+1/21+1/42+1/42 [A020327]
La 2021e décimale de π est un 8, la 2021e décimale de e est un 8, la 2021e décimale du nombre d'or φ est un 8. Chouette coïncidence. [A266002]
Et la santé !
Solution du puzzle : les trois ceintures de l'ennéamino :
Ai-je encore des scripts de vidéos en retard à poster ? Bien sûr que oui. Vais-je les poster en janvier ? Ça serait une bonne résolution à prendre. Mais il y a une résolution que je ne mettrai pas de côté de sitôt, répondre à la question que tout le monde se pose en ce 1er janvier 2020 : cette nouvelle année sera-t-elle intéressante ?
La méthodologie est toujours la même. Une année est intéressante si et seulement si elle présente de nombreuses occurences dans l'OEIS, l'encyclopédie en ligne des suites entières. Les années 2018 et 2019 furent assez quelconques, avec seulement une centaines de propriétés intéressante. Pourtant, 2020 sera...
Pas mal. Pas ouf, mais pas mal.
Nombre de propriétés répertoriées par l'OEIS pour chaque année. Théorème : plus une année est intéressante, plus elle a de propriétés, et réciproquement
Avec 251 propriétés, l'année 2020 est donc la quatrième année la plus intéressante de la décennie. Sa décomposition en produit de facteurs premiers est 2020=2×2×5×101, ce qui l'empêche de bénéficier des propriétés inhérentes aux années premières, mais grâce à ses seuls chiffres 0 et 2, elle récupère des propriétés des nombres écrits en base 3 (et il y en a beaucoup).
Regardons en détail quelques propriétés qui rendent ce nombre 2020 unique.
2020 est un nombre autobiographique curieux [A046043] Un nombre est auto-descriptif si, comme son nom l'indique, il se décrit lui-même. C'est par exemple le cas du nombre 10153331, qui possède 1 fois le chiffre 0, 1 fois le chiffre 5, 3 fois le chiffre 3 et 3 fois le chiffre 1. Notons que 10153331 est le plus petit nombre premier à vérifier cette propriété. Il n'existe qu'un nombre fini de nombres auto-descriptifs, allant de 22 jusqu'à 9998979595959595848484848484848476737373737373736262626262625151515110 (vous pouvez vérifier que ce nombre possède 9 fois le chiffre 9, 9 fois le chiffre 7, etc.)
On y distingue les nombres autobiographiques. Le nombre 10213223 est un autobiographique, puisqu'il se décrit lui-même dans l'ordre : il possède 1 fois le chiffre 0, 2 fois le chiffre 1, 3 fois le chiffre 2 et 2 fois le chiffre 3. Les chiffres décits (en rouge) sont ici dans un ordre croissant, ce qui fait du nombre 10213223 le plus petit entier (après 22) à vérifier cette propriété. Un tel nombre ne peut pas avoir plus de 20 chiffres, le plus grand d'entre eux est alors 101112213141516171819.
Le nombre 2020 est un nombre autobiographique curieux, mais d'une façon un peu différente, puisque les chiffres décrits (en rouge) sont sous-entendus. Dans le nombre 2020, il y a 2 fois le chiffre 0, 0 fois le chiffre 1, 2 fois le chiffre 2 et 0 fois le chiffre 3. Il n'existe que 7 nombres autobiographiques curieux, 2020est le deuxième (le premier étant 1210).
Un spirale à 5 centres après 20 tours a une longueur de 2020π [A202803] Construisons une spirale à 5 centres. Pour cela, on part d'un pentagone régulier ABCDE de côté 1 à partir duquel on construit 5 demi-droites [BA), [CB); [DC), [ED) et [AE). On construit alors entre les demi-droites [BA) et [CB) un arc de cercle centré en B passant par A, puis on le prolonge entre les demi-droites suivantes en le centrant sur le sommet suivant C, et ainsi de suite. Après 5 arc, la spirale construite fait un tour et on peut calculer sa longueur : le premier arc construit a en effet un rayon de 1, le suivant de 2 et ainsi de suite. Chaque arc décrivant un angle de 2π/5, on en déduit que la longueur de la spirale après un tour est de 1×2π/5 + 2×2π/5 + 3×2π/5 + 4×2π/5 + 5×2π/5 = (1+2+3+4+5)×2π/5 = 6π.
De manière générale, si la spirale fait n tours, sa longueur sera [1+2+3+...+5n]×2π/5 = [5n×(5n+1)/2]×2π/5 = n×(5n+1) π. Pour 20 tours, cela donne donc une longueur de 2020 π.
Spirale à 5 centres et 20 tours. Sa longueur est de 2020π. Dans chaque portion du plan délimitée par les demi-droites, les arcs de cercles sont concentriques.
Le nombre 12 a 2020 partitions overcubiques [A246584] Combien y a-t-il de façons d'écrire le nombre 4 sous la forme d'une somme décroissante d'entiers non nuls ? Détaillons :
4 = 1+1+1+1 = 2+1+1 = 2+2 = 3+1 = 4
Il y a donc 5 façons d'écrire 4 sous la forme d'une somme. On dit donc que 4 a 5 partitions. Ces partitions ont particulièrement été étudiées par le mathématicien d'origine indienne Ramanujan qui en a tiré de nombreuses propriétés. L'une d'elle, la "congruence de Ramanujan", indique que pour un nombre sur 5, les partitions sont divisibles par 5 (plus précisément, si on note p(n) le nombre de partitions de n, alors p(5k+4)=0 [mod 5]). L'étude des partitions a également amené Ramanujan a étudier sa série génératrice, donnée par la jolie formule suivante :
Et si, pour une obscure raison, on considère les décompositions suivantes :
les nombres pairs peuvent prendre 4 couleurs différentes - disons bleu/rouge/vert/orange - et dont deux couleurs - disons vert/orange- qui apparaissent au plus une fois
les nombres impairs peuvent prendre 2 couleurs différentes - disons bleu/rouge - dont une - disons rouge - qui apparait au plus une fois
Dans ce cas, le nombre de partitions est bien plus grand, puisqu'il s'élève à 26 :
On dit alors que 4 a 26 "partitions overcubiques", ce qui est une notion de théorie des nombres dont on peine au premier abord à comprendre les motivations qui ont mené à son existence. En réalité, ce qui a amené à l'introduction de ces partitions est leur série génératrice, qui généralise celle des partitions, et qui permet d'étudier les congruences de Ramanujan sous un nouvel angle.
Mais aussi...
2020 est la concaténation d'une paire de nombres identiques, au même titre que 1515 ou 4242 (A020338)
La somme des chiffres de 2020 est égal à son nombre de chiffres (A061384)
le nombre 20203 n'a que des chiffres pairs (ce qui est bizarrement plutôt rare) (A052004)
[Edit, via David Draï] On a 2020 = 17² + 19² + 23² + 29², ce qui est la somme de quatre nombres premiers consécutifs (A133524)
Une nouvelle année qui commence, et toujours la même question. Que peut-on attendre de cette année qui pointe le bout de son nez ? Pour la dixième fois, nous allons nous tourner vers l'oracle ultime, celui qui est capable de prédire avec une précision inégalableréférence nécessaire l'intérêt d'une année donnée. Ce médium, c'est l'OEIS, l'encyclopédie en ligne des suites entières, qui regroupe toutes ls suites de nombres ayant des propriétés intéressantes. Plus un nombre est intéressant, plus on la retrouvera dans les suites de l'OEIS. Pour mesurer l'intérêt d'une année, il est donc nécessaire et suffisantréférence plus que nécessaire de compter le nombre d'occurences de ce nombre au sein de l'OEIS.
Les nombres 2016, 2017 et 2018 possèdent respectivement 946,490 et 128 propriétés intéressantes au moment où j'écris ces lignes. Les années 2016, 2017 et 2018, vous l'avez sans doute remarqué, étaient respectivement incroyablement intéressantes, plutôt intéressante, et plutôt banale. Que peut-on annoncer pour 2019 ?... Eh bien, cette année sera
Assez quelconque ! Désolé de vous l'annoncer comme ça...
Nombre de propriétés de chaque années répertoriées dans l'OEIS L'OEIS permet de déterminer l'intérêt d'une année. Cette outil ne possède aucune faille méthodologique.
Selon l'encyclopédie, le nombre 2019 possède donc 121 propriétés, soit à peu près autant que l'année dernière. Encore, donc, un nombre qui n'a pas beaucoup d'intérêt. Il ne s'agit pas d'un nombre figuré (ni triangulaire, ni carré, ni hexagonal, ni rien du tout) et il n'est même pas premier (puisque 2+0+1+9 est divisible par 3, c'est que 2019 est divisible par 3). La décomposition de 2019 en produit de facteurs premiers est 2019=3×673, et c'est l'un des trucs les plus intéressants que l'on peu raconter sur 2019.
Cherchons tout de même davantage, et explorer l'OEIS en quête de propriétés vraiment intéressantes.
Côté d'un nombre triangulaire qui est la somme de deux nombres triangulaires dont la différence est aussi un nombre triangulaire [A185257] Un nombre triangulaire, c'est un nombre que l'on peut figurer sous la forme d'un triangle équilatéral :
Les premiers nombres triangulaires sont 1, 3, 6, 10 et 15
Mais bon, 2019 n'est pas du tout un nombre triangulaire. La dernière année triangulaire, c'était 2016, qui est le 64e nombre triangulaire, et je vous invite à relire l'article que j'ai écrit à l'époque pour davantage de détails.
En tout cas, ce que l'on peut dire d'un nombre triangulaire, c'est que le N-ième nombre triangulaire, noté ΔN, c'est le nombre ΔN=1+2+3+4+...+N, ce qui est égal à ΔNN(N+1)/2. Réciproquement, si un nombre peut s'écrire sous la forme N(N+1)/2, c'est que c'est ΔN, le N-ième nombre triangulaire.
Prenons Δ8, le 8-ème nombre triangulaire. Il s'agit de Δ8 = 8×9/2 = 36. Sauf que 36=21+15, or, 21 et 15 sont tous les deux des nombres triangulaires (21=Δ6 et 15=Δ5). Mais cette décomposition est encore plus intéressante : non seulement 21+15 est un nombre triangulaire, mais c'est aussi le cas de 21-15=6, qui est le troisième nombre triangulaire. On a donc les deux égalités :
Δ6 + Δ5 = Δ8 Δ6 - Δ5 = Δ3
Ou, sous forme plus imagée :
Des nombres triangulaires décomposables en somme de deux nombres triangulaires, il y en a beaucoup, mais que la différence soit aussi triangulaire, c'est plus rare. Le nombre Δ8 = 36 est le plus petit exemple, mais il y a aussi Δ23 = 276, puisque Δ18 + Δ14 = Δ23 et Δ18 - Δ14 = Δ11 :
Là où ces nombres nous intéressent, c'est que c'est aussi le cas de Δ2019 = 2019 × 2020/2 = 2 039 190, puisque 2 039 190 = 1023165 + 1016025 et 1023165 - 1016025 = 7140. Dit autrement :
Δ1430 + Δ1425 = Δ2019 Δ1430 - Δ1425 = Δ119
Evidemment, je n'en ferai pas de représentation graphique...
Premier nombre à 4 chiffres qui apparait 6 fois dans les décimales de π [A276686]
Voici les 5648 premières décimales de π (en base 10) :
Intéressant : le nombre 2019 y apparait 6 fois. C'est en fait le premier nombre à 4 chiffres qui apparait 6 fois dans les décimales de π. À titre de comparaison, les seules autres années de la décennie qui apparaissent dans ces décimales sont 2010 (deux occurences), 2014 (une occurence) et 2018 (une occurence). A noter également que la première occurence de 2019 apparait en position 244 dans les décimales de π, ce qui est particulièrement tôt. Comme le remarque Mickael Launay, c'est la première fois que l'on peut écrire les décimales de π dans un tweet jusqu'à faire apparaitre le numéro de l'année. la prochaine fois, ça sera en 2089.
Nombre heureux d'être chanceux [A091431] Le nombre 2019 est à la fois heureux et chanceux.
Un nombre est heureux si, quand on répète le calcul de la somme du carré de ses chiffres (en base 10), on tombe sur 1. Le nombre 2019 est heureux, a preuve : 2²+0²+1²+9² = 4+0+1+81 = 86 → 8²+6² = 64 + 36 = 100 → 1²+0²+0² = 1+0+0 = 1 Le nombre 4, lui est malheureux, puisque l'itération de ces opérations boucle : 4 → 16 → 37 → 58 → 89 → 145 → 42 → 20 → 4 → ... En fait, si un entier n'est pas heureux, sa suite finira toujours pas tomber dans la boucle du nombre 4.
Un nombre est chanceux lorsqu'il n'est pas éliminé dans le crible suivant, qui peut rappeler le crible d'Erathostène : → on part de la liste des entiers naturels strictement positif : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45... → on retire un nombre sur 2 : 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45... → Le 1 est à présent sauvé. le premier qui reste est 3, retirons-donc un nombre sur 3 : 1 3 7 9 13 15 19 21 25 27 31 33 37 39 43 45... → Le 3 est à présent sauvé. le premier qui reste est 7, retirons-donc un nombre sur 7 : 1 3 7 9 13 15 21 25 27 31 33 37 43 45 ... → Le 7 est à présent sauvé. le premier qui reste est 9, retirons-donc un nombre sur 9 : 1 3 7 9 13 15 21 25 31 33 37 43 45 ... → etc.
En poursuivant le processus d'élimination, on pourra s'apercevoir que le 273e nombre sauvé sera 2019, ce qui fait de lui un nombre chanceux (qui sont quand même particulièrement nombreux, à vrai dire)
Être à la fois heureux et chanceux, ce n'est pas vraiment une propriété rare (c'était par exemple le cas pour 1995, mais cela ne se reproduira pas avant 2115), le nombre 2019 est en fait le 46e à vérifier les deux propriétés.
Mais aussi...
2019 est la somme des 22 premières puissances parfaites : 2019 = 1+4+ 8+ 9+ 16+ 25+ 27+ 32+ 36+ 49+ 64+ 81+ 100+ 121+ 125+ 128+ 144+ 169+ 196+ 216+ 225+ 243 [A076408]
Le plus grand nombre premier connu de la forme 17n-16 est 172019-16 [A034922]
Bref, à défaut d'être une année intéressante, l'année 2019 sera heureuse et chanceuse, et peu d'années peuvent en dire autant. C'est déjà pas mal.
Retour en vidéo sur l'une des plus grande conjecture du XXe siècle, la conjecture de Poincaré.
Script + commentaires
En 2003, Grigori Perelman résout l’un des plus important problème de topologie, un problème ouvert depuis presque un siècle. Grâce à cette démonstration, il remporte les un millions de dollars réservés au premier mathématicien qui viendrait à bout du problème, une récompense qu’il refusera avant de claquer la porte des mathématiques académiques, et de retourner vivre chez sa mère dans un faubourg de Saint-Petersbourg. Ce qu’il a résolu, c’est la conjecture de Poincaré, et ça tombe bien, j’ai deux minutes pour en parler.
En 2000, l’institut Clay propose à la communauté mathématique la liste des problèmes du prix du millénaire. Cette liste, c’est sept problèmes ouverts et centraux dans leur domaine respectif, et cela serait appréciable de les voir résolus avant l'an 3000. Pour donner encore plus d’importance à ces sept conjectures, l’institut Clay a prévu de récompenser celui ou celle qui arriverait à terrasser l’une d’entre elles : un million de dollars. Rares sont les mathématiciens qui travaillent sur ces questions en espérant gagner cette somme, mais il est difficile de passer à côté du prestige que représentent ces sujets. Il n’y a qu’à voir l’engouement provoqué par Michael Atiyah en septembre 2018 lorsqu’il a annoncé avoir démontré l’hypothèse de Riemann. D'ailleurs, la "preuve" de la conjecture de Riemann proposée par Atiyah n'a pas du tout convaincu la communauté mathématique. Il faut dire qu'elle ne fait que 5 pages, et beaucoup de propriétés de la fonction annexe qu'il utilise sont omise; En fait, ce qu'il a réellement proposé, c'est plutôt une piste de recherche vers la résolution de la conjecture.
La conjecture de Poincaré, aujourd’hui théorème de Perelman, s’énonce ainsi : toute variété compacte simplement connexe et sans bord à trois dimensions est homéomorphe à une 3-sphère. Si tu es un profane de topologie, le seul terme mathématique que tu as du comprendre de cet énoncé, ça doit être le mot “trois”. Alors on va tâcher d’expliquer ce que sont les variétés, les 3-sphères, ainsi que tous les qualificatifs qui s’y raccrochent. Bref, voici une introduction à la topologie.
Mettons nous en situation. Voici Mario, un plombier américano-italien affecté à l’entretien des égouts de New-York dans le jeu Mario Bros sorti en 1983 sur borne d’arcade, puis dans de nombreux autres portages sur différentes consoles Nintendo. Sa mission est de nettoyer la zone rectangulaire des carapeurs, des zarbipas et des mouchaks, mais tout ça n’a rien à voir avec la conjecture de Poincaré. Ce qui est notable, c’est que Mario peut se déplacer suivant plusieurs directions. Déjà, il peut se déplacer horizontalement, en marchant vers la droite ou vers la gauche. Mais il peut aussi se déplacer verticalement, vers le haut ou vers le bas, en effectuant des sauts. Puisque Mario peut toujours se déplacer selon deux directions quel que soit l’endroit où il est dans la zone de jeu, on peut qualifier l’espace dans lequel il évolue de variété topologique à deux dimensions. En simplifiant un peu, on peut dire qu’une variété topologique est un espace dans lequel on peut se déplacer, et ça selon toujours le même nombre de directions quel que soit l’endroit où l’on se trouve dans cet espace. Ce nombre de directions, c’est ce que l’on appelle la dimension de l’espace. L’espace de jeu de Mario Bros. possède donc deux dimensions. En fait, Mario ne limite pas ses déplacements à seulement deux directions, puisqu’il est aussi possible de faire des sauts qui ne sont pas verticaux. Des déplacements suivant des directions obliques sont donc permises. Seulement, on peut remarquer qu’un déplacement oblique, c’est en fait la composition d’un déplacement horizontal et d’un déplacement vertical. Cette direction oblique n’est donc pas vraiment une direction supplémentaire, l’espace de jeu n’est bien composé que de deux directions fondamentales, que l'on appelle "libres" : l’horizontale et la verticale. Ce qui fait que la zone de jeu est bien à deux dimensions.
Précisons un petit peu plus. Lorsque Mario a ses deux pieds qui touchent le sol, il n’est pas complètement libre de ses mouvements. Selon la direction horizontale, il a accès à la droite et à la gauche, mais selon la direction verticale, il n’a pas accès au bas, seulement au haut. Dans une telle situation où un espace est infranchissable dans un sens donné, on dira que l’on a affaire à un bord. Mario vit non seulement dans une variété, mais cette variété est une variété à bord. Pour simplifier un peu la modélisation, on supposera que les seuls bords sont ceux du sol et d’un plafond (qui n'existe d'ailleurs pas dans le jeu), et que les plates-formes n’existent plus. On admettra aussi que Mario peut voler, parce que c’est moi qui modélise, et je fais ce que je veux. Mais le monde de Mario Bros a un petit plus non négligeable : les côtés droits et gauches de l’écran ne sont pas des bords. Quand Mario franchit le côté droit de l’écran, il réapparait à la même hauteur sur le bord gauche de l’écran, et réciproquement. En tant que joueur, on peut l’interpréter comme une téléportation, mais Mario ne le remarque pas, il s’est simplement contenté d’avancer dans une direction. Les bords droits et gauches de l’écran ne sont donc pas vraiment des bords. Le monde de Mario Bros. n’est donc pas qu’un simple rectangle, c’est plus que ça : il s’agit en fait d’un cylindre. Enfin, pour être plus précis, l’espace de jeu de Mario Bros. est homéomorphe à un cylindre, c’est à dire qu’il est possible de déformer l’un en l’autre et réciproquement sans déchirure. Prenons un autre exemple de variété qui n'a rien à voir, l’espace des positions acceptables que l'on peut prendre dans un lit, en admettant que les mouvements autorisés consistent à se déplacer le long de son traversin, ou bien se tourner sur soi-même. L’espace des positions est une variété à bord. C'est une variété, puisque, quelle que soit la position dans laquelle on se trouve, on peut toujours se déplacer selon la direction droite/gauche, ou selon la direction horaire/anti-horaire. Mais elle possède un bord, puisqu'il arrive un moment où on ne peut plus continuer vers la gauche, et de même vers la droite. On peut alors se représenter l'espace des positions sous une forme graphique, où l'axe des abscisses représente la position sur le traversin, et l'axe des ordonnées l'angle de rotation. Dans cette représentation, deux côtés du carré sont des bords, et deux autres côtés se correspondent. L'espace des positions acceptables pour dormir est donc équivalent au monde de Mario : c'est un cylindre !
Parce que, en effet, c’est ça la topologie, l’étude des points communs entre des objets à une déformation près. Quand un topologiste dit que deux trucs sont les mêmes, cela signifie qu’il est possible de déformer l’un en l’autre, et réciproquement. Pour cette catégorie de mathématiciens, l’alphabet latin majuscule ne possède que 8 lettres vraiment différentes, puisque, fondamentalement, un U, un Z, un L ou un M, c’est la même chose, à un homéomorphisme près, puisque ce ne sont que des segments plus ou moins déformés. Notons que de toutes les lettres de l’alphabet, seules 14 sont des variétés, plus précisément à une dimension. Il y a celles qui sont homéomorphe à un segment, comme J ou M, ou celles qui sont homéomorphe à un cercle, comme O ou D. En effet, si on se déplace dans l’une de ces lettres, on ne pourra que avancer ou reculer et ça quel que soit l’endroit où l’on s'y trouve, mais jamais aller dans une autre direction. La lettre T, au contraire, n’est pas une variété, puisqu’il existe un point où on peut changer de direction. On a donc déjà deux exemples de variétés de dimension 1, que l'on appelle plus couramment les courbes. En bon matheux, on veut savoir si il existe d’autres exemples, il faut donc s’atteler à la classification des différentes variétés de dimension 1 qui existent. On peut par exemple parler du symbole “=”, qui est aussi une variété de dimension 1, mais qui a le désavantage d’être composé de plusieurs morceaux distincts. On dit qu’il n’est pas “connexe”. Il y a aussi les droites. Ce sont bien des variétés de dimension 1, mais elles ont pour moi une caractéristique en trop : elles s’étendent à l’infini. Les droites ne sont pas bornées. On peut résoudre le problème, puisqu’il est possible de déformer une droite de manière à la ramener à un intervalle ]0,1[ ouvert, c’est à dire l’ensemble des nombres strictement compris entre 0 et 1. Mais ça, ça ne me plait pas non plus, puisque le segment obtenu n’est pas fermé, ce qui arrive quand des points limites n’appartiennent pas à l’ensemble. Quand une variété est à la fois fermée et bornée, on dit qu’elle est compacte, ce qui n'est donc pas le cas de la droite. Oui, cette définition de la compacité pique les yeux pour un topologiste, et pour de bonnes raisons. Sans rentrer dans les détails, pour qu'un espace puisse être qualifié de "fermé", il faut qu'il soit à l'intérieur d'un espace plus grand ; pourtant, il n'y a aucune raison a priori de penser qu'un espace comme ceuli de Mario soit à l'intérieur d'un espace plus grand (d'ailleurs, pour le faire, il a fallu passer de la 2D à la 3D, ça n'a donc rien d'évident). Même remarque avec le fait d'être borné, où il faut en plus que l'espace plus grand soit métrique. Heureusement, les variétés de dimensions finies peuvent toujours être vues comme des sous-espaces d'espaces plus grand (Théorème de plongement de Whitney). Un espace topologique (séparé) est dit "compact" quand, de tout recouvrement par des ouverts, on peut extraire un sous-recouvrement fini. C'est plus précis (et encore...), mais beaucoup trop abstrait pour une vidéo de vulgarisation. . Quand on regarde finalement les différentes courbes qui existent, on peut alors énoncer le théorème suivant : si une variété de dimension 1 est à la fois connexe et compacte, alors elle sera homéomorphe soit à un cercle, soit à un segment.
Ça, c’était pour la classification des variétés de dimension 1. Mais quelles sont les différentes variétés qui existent en dimension 2, appelées plus couramment les surfaces ? On a déjà parlé du cylindre, et on peut en ajouter quelques autres qui sont évidents, comme le plan infini R², le plan dans lequel on a l’habitude de faire de la géométrie, ou bien le disque B2, qui est une variété dont le bord est un cercle. Observons maintenant des espace 2D plus exotiques, comme celui de Sonic. Plus précisément, quelle est la forme des blues sphères, les niveaux secrets introduits dans Sonic 3, en 1994 sur Mega Drive. Dans cet environnement, Sonic a le choix entre aller devant ou derrière lui, ou bien aller à droite ou à gauche, ce qui en fait une variété de dimension 2. Visuellement, cela ressemble à une sphère, qui est un bon exemple de variété de dimension 2, mais il faut se méfier des apparences. En fait, si Sonic se déplace en ligne droite dans une direction, il finira par revenir à son point de départ. En se déplaçant sur cette surface, on vient donc de tracer un lacet, c’est à dire, une courbe qui boucle sur elle-même, comme j'en avais parlé dans ma vidéo sur le théorème de Jordan. Obtenir un lacet en marchant toujours dans la même direction, c’est parfaitement envisageable sur une sphère; mais là où la blue sphère est différente, c’est si on fait la même chose selon une autre direction. Là aussi, on reviendra au point de départ, mais sans avoir entre temps recroisé le lacet précédent. Sur la surface d’une sphère, c'est quelque chose d'impossible : si deux lacets se coupent une fois, ils se couperont une deuxième fois. La blue sphère de Sonic n’est donc pas déformable en une sphère, mais en autre chose : elle a plutôt la forme d’un donut ou d’une bouée, c’est à dire, d’un tore. En effet, quand on regarde les plans, les côtés coïncident deux à deux. Si on déforme cette carte, on obtient dans un premier temps un cylindre en faisant coïncider les bords droits et gauche, puis dans un deuxième temps le tore en faisant coïncider les bords maintenant circulaires hauts et bas. On a le même phénomène dans le jeu Asteroids, où les bords droits et gauche de l'espace coïncident, mais aussi les bords hauts et bas. La planète du jeu Chrono Trigger a elle aussi ces propriétés toriques. Bref, on peut ajouter le tore dans ma liste des variétés à deux dimensions. Le tore est donc un objet compact, connexe et sans bord, mais a la particularité de former, quand on le regarde depuis notre espace de dimension 3, un trou. Un seul trou. On peut généraliser ces histoires de trous, et donc évoquer le double tore, à deux trous, le triple tore, à trois trous, et je vous laisse extrapoler au nombre de trous que vous désirez.
Revenons à l’univers de Mario, et parlons du jeu de course de la franchise, Mario Kart. Dans Mario Kart Double Dash, on peut s’affronter dans le parc Baby. Les véhicules peuvent avancer, reculer et tourner, la piste est bien une variété de dimension 2. Elle possède un bord et boucle sur elle même, le circuit est donc homéomorphe à un cylindre, puisqu’il est possible de déformer l’un pour obtenir l’autre. Dans la franchise, la plupart des circuits sont topologiquement équivalents à des cylindres, mais l’un d’eux fait vraiment exception : le circuit Mario, présent dans Mario Kart 8. Le circuit est toujours une variété à bord de dimension 2, mais il a quelque chose de supplémentaire. Quand notre personnage a effectué la moitié d’un tour, on peut s’apercevoir que l’on est revenu à notre point initial, mais de l’autre côté de la ligne de départ, du côté pile de la route. Le circuit Mario n’est pas un cylindre, mais un ruban de Möbius. Un ruban de Möbius, c’est ce que l’on obtient lorsque l’on recolle sur lui-même un ruban après lui avoir fait faire un demi-tour. Cette variété à bord a plein de propriétés intéressantes, comme le fait que son bord est homéomorphe à un seul cercle, ou que le couper en deux dans le sens longitudinal ne la coupe pas vraiment en deux. De la même façon que l’on peut voir un cylindre dans la forme des égouts de Mario Bros. ou d’un tore dans la forme de l’univers d'Asteroids, il est possible d’envisager le ruban de Möbius comme la forme d’un espace de jeu rectangulaire. On peut imaginer un jeu vu du dessus, où lorsque le personnage quitte l’écran en bas du côté droit, il réapparaît en haut du côté gauche, comme si passer d’un côté à l’autre revenait à faire une symétrie d’axe horizontal. C’est cette symétrie axiale qui correspond au demi-tour du ruban de Möbius. La conséquence, c’est que si notre personnage fait le tour de la zone de jeu, il reviendra à son point de départ après avoir subi une symétrie. Dans ce cas, c’est qu’il ne sera plus superposable avec son frère jumeau qui l’a attendu bien sagement. Quand une telle situation se présente, on dit que la surface n’est pas “orientable”. Bref, le ruban de Möbius s’ajoute à notre collection de variétés de dimension 2. Il y a aussi le petit frère du ruban de Möbius, lui aussi à bord et non orientable, le slip de Möbius, mais je ne rentrerai pas dans le détail. On peut aussi ajouter d’autres surfaces non orientables, comme la bouteille de Klein, qui est ce que l’on obtient quand on cout deux rubans de Möbius bord à bord, ou le plan projectif, que l’on obtient en recollant un ruban de Möbius sur lui-même. N’essayez pas de faire ces constructions à la maison, elles sont impossibles à faire depuis notre monde à trois dimensions, les surfaces ayant la fâcheuse propriété de s'auto-intersecter dans notre espace à trois dimension. Et pour compléter la collection, j’ajouterai qu’il est possible, de la même façon que coller deux tores permet de donner des doubles tores, de coller ensemble des plans projectifs. En collant un plan projectif sur un autre, on obtient une bouteille de Klein, et en collant davantage, on obtient des surface non orientables un peu plus exotiques. Bref, on a tout une collection de variétés de dimensions 2 dans lequel on va essayer de faire un peu de tri. Déjà, on ne va garder que les variétés compactes, il y a trop de choses bizarres qui arrivent quand on s’approche de l’infini. Au revoir, donc, au plan infini R². Ensuite, on va se débarrasser des variétés à bord, beaucoup trop complexes. Au revoir donc au disque, au cylindre et aux rubans de Möbius. Finalement, si on se restreint aux variétés connexes, compactes et sans bord, il ne nous reste que trois familles : il y a la sphère, les tores à 1 ou plusieurs trous, oules plans projectifs et tous ses descendants. Toute surface connexe compacte et sans bord est donc homéomorphe à l’une de ces variétés, c’est le théorème de classification des variétés de dimension 2.
Mais de toutes ces surfaces, une se dégage du lot, il s’agit de la sphère et c’est en fait l’objet de la conjecture de Poincaré. En effet, la sphère a la propriété d’être simplement connexe, c’est à dire que si un élastique se trouve sur sa surface, il sera toujours possible de le réduire jusqu’à ce qu’il ne forme plus qu’un seul point. A contrario, un tore n’est pas simplement connexe, puisqu’un élastique sur sa surface ne peut pas toujours être réduit en un point, par exemple si celui-ci en fait le tour. Le problème est le même à la surface d’une bouteille de Klein, où l’élastique peut être prisonnier de son anse. Bref, toute variété compacte simplement connexe et sans bord à deux dimensions est homéomorphe à une sphère. C’est ça, la conjecture de Poincaré, mais il s’agit là de la variante en deux dimensions, celle qui en fait était facile et que Poincaré a résolu.
La véritable conjecture de Poincaré énonce que toute variété compacte simplement connexe et sans bord à trois dimensions est homéomorphe à une sphère en 3 dimensions. Et autant le dire toute suite, mettre de l’ordre dans les variétés de dimension 3, c’est loin d’être une partie de plaisir. On peut quand même essayer de sentir à quoi ressemble ces variétés, en essayant de répondre à cette question : quelle est la forme de l’Univers ? Rien que ça.
Une chose sur lequel on peut se mettre à peu près d'accord, c'est que l'Univers tel qu’on peut le sentir à notre échelle est une variété de dimension 3, puisque, quel que soit le point où je me trouve dans l'univers, j’aurai toujours la possibilité de se déplacer suivant trois directions libres. Puisque l'Univers a un peu moins de 14 milliards d'années, la lumière qui arrive du plus loin de l'Univers a voyagé pendant ces 14 milliards d'années à sa vitesse de croisière de 300 000 km/s. En prenant en compte l'expansion de l'univers, on peut calculer que les objets visibles les plus éloignés de nous sont aujourd'hui éloignés de 46.5 milliard d’années-lumières. La forme de l'Univers, c'est donc une boule dont le rayon est de 46.5 milliards d’années-lumières et dont le centre, c'est nous. Ou plutôt, c'est l'univers observable qui a la forme de cette boule, ce qui donne un premier exemple assez simple de variété de dimension 3. Pour l'univers au complet, la question n'est pas aussi évidente qu'elle n'y paraît. La première idée de n'importe qui, c'est de dire que l'univers est infini. Et infini dans toutes les directions, tant qu'à faire. Il aurait donc la forme de l'espace de la géométrie euclidienne, R<sup>3</sup>. Et pourtant, il pourrait tout à fait en être autrement. Il est tout à fait envisageable qu'il soit compact, ou, pour simplifier, que son volume est fini, et ça, sans pour autant avoir le moindre bord. Il est en effet assez inconcevable que l'Univers puisse posséder des murs. De la même façon que le vaisseau de Asteroids vit dans un univers compact et sans bord que l'on peut interpréter comme un tore, nous vivons peut-être dans un univers qui pourrait être compact et sans bord, comme un tore tridimentionnel. Essayons de visualiser cette éventualité. La Terre est au centre de l'Univers observable, qui est une boule. Imaginons que cette boule est à l'intérieur d'un immense cube, dont le rayon est supérieur au diamètre de l'Univers observable. Si nous vivons dans un Univers torique, cela signifie que lorsque l'on franchit l'une des faces de ce cube, on se retrouverait au même point sur la face opposée. L'Univers entier est donc entièrement contenu dans ce cube, de la même façon que l'Univers entier d'Astroids est dans un simple rectangle. Dans un Univers torique vu de l'intérieur, on pourrait voir la Terre en regardant dans tout un tas de directions. Il est aussi tout à fait envisageable de se déplacer en ligne droite toujours dans la même direction, et de pourtant parvenir à revenir à son point de départ, comme c'était le cas sur la surface d'un tore. Même si ce n'est pas aujourd'hui l'hypothèse privilégiée, l'hypothèse de l'Univers torique n'est pas rejetée par les spécialistes de la question de la topologie de l'Univers. En tout cas, voilà qui rajoute une carte dans notre collection de variétés 3D.
D'autres variétés, et donc, d'autres Univers, sont aussi envisageables, comme le tore hexagonal, ou le cube est remplacé par un prisme hexagonal. Il y a aussi l'espace cubique quart de tour, où des rotations sont faites au moment de recoller les faces du cube-univers ou bien l'espace dodécaédrique de Poincaré, un des prétendants principaux au titre de forme de l'Univers, si on en croit Jean-Pierre Luminet. Et ça, ce ne sont que quelques exemples parmi de très nombreux autres. Un peu plus étonnant, certaines d'entres elles sont des équivalents tridimentionnel du ruban de Möbius ou de la bouteille de Klein, c'est à dire, non orientable. Prenons par exemple l'espace torique de Klein. Il faut à nouveau imaginer que la Terre est au centre d'un immense cube, et lorsque l'on traverse l'une des faces, on se retrouve au niveau de la face opposée, après une symétrie axiale. Dans un tel univers, on peut partir de sa galaxie et y revenir après un simple voyage en ligne droite, mais à un détail près. Quand vous retrouverez votre point de départ, tout sera à l'envers, comme si vous veniez de traverser un miroir : vos amis auront le coeur à droite, l'eau chaude ne sera pas du bon côté du robinet, et les anglais rouleront enfin du bon côté de la route. Cette topologie n'est pas vraiment privilégiée chez les cosmologistes, mais je trouve que ça donnerait un bon scénario de SF. D'ailleurs, c'est le synopsis du film "Danger planète inconnue, où l'on découvrre l'existence d'une Terre miroir, symétrique de la Terre par rapport au Soleil. Bref, cela ajoute encore plus de diversité à notre collection de variétés 3D.
Il reste pourtant un espace topologique à 3 dimensions dont je n'ai pas encore parlé et qui est au coeur de la conjecture de Poincaré, celui appelé S3, l'hypersphère, ou la 3-sphère. Pour comprendre ce que c'est, il est important de bien faire la distinction entre une sphère et une boule. Quand on parle d'une sphère sans plus de précisions, on parle de S2, la 2-sphère, qui est grosso modo la forme d'un ballon de basket, d'une balle de ping-pong voire d'un ballon de rugby puisqu'en topologie tout est déformable. Une 2-sphère, c'est juste une surface, ça n'a que deux dimensions, c'est quelque chose de creux. Au contraire, la boule B3, ou plutôt, la 3-boule c'est un objet à 3 dimensions, c'est plein. C'est donc la forme d'une boule de billard ou de bowling. Une 3-boule, c'est donc une variété 3D à bord, et son bord, c'est la 2-sphère, qui est une variété 2D sans bord. Tout ça peut se généraliser, mais pour s'en convaincre, il faut revenir aux définitions. Une sphère S2, c'est l'ensemble des points de l'espace situé à une même distance d'un point donné, son centre. Si on prend la même définition mais dans le plan, on retrouve S1, le cercle, et sur une droite, cela donne S0, un couple de point. De façon équivalente, on définit la boule B3 comme l'ensemble des points de l'espace dont la distance à un point donné, le centre, est inférieure ou égale à une distance donnée. En généralisant au plan, cette définition nous donne le disque B2, c'est à dire un cercle plein, et en une dimension, on obtient le segment, B1.
On peut aussi généraliser tout ceci à un hyper-espace à 4 dimensions : la 3-sphère S3, c'est donc l'ensemble des points de l'hyper-espace situés à une distance donnée d'un point, son centre. Mais bon, on est pas tellement avancé, puisque c'est évident pour personne de voir en dimension 4. Essayons plutôt de le construire depuis notre espace 3D, comme on a construit un hypertore en recollant les faces d'un cube.
Pour ça, faisons un peu de bricolage. Si je prends deux segments B1, que je mets un peu de colle topologique sur leur bord S0, que je les déforme un peu puis les assemble et que j'attends un peu que ça sèche, j'obtiens un cercle parfait S1. De même, si je prends deux disques B2, que je mets de la colle topologique sur leur bord S1, et que je les déforme un peu puis les assemble, j'obtiens une sphère S2. La construction se généralise : si je prend deux boules B3, que j'applique un peu de colle sur la sphère S2 qui leur sert de bord, et que je les recolle l'un sur l'autre, j'obtiens donc la fameuse 3-sphère. Bien sûr, ce recollement est impossible à réaliser en pratique, mais donne une représentation abstraite de la topologique de la 3-sphère. Finalement, on peut voir la 3-sphère comme deux boules où les points du bord de l'un sont en correspondance avec les points du bord de l'autre. On peut alors imaginer un vaisseau qui se déplacerait dans un univers dont la topologie serait celle d'une hypersphère. Disons qu'il parte du centre de la première boule et qu'il voyage tout droit dans une direction. À un moment donné, il atteindra la frontière de la première boule, arrivera dans la deuxième boule, poursuivra son voyage jusqu'au centre de cette deuxième boule. En continuant sur son trajet, il finira fatalement par revenir à son point de départ. Il faut bien comprendre qu'il n'y a pas eu de téléportation entre la première et la deuxième boule, c'est juste une façon de représenter les choses ; on peut faire l'analogie avec la Terre, qui est une sphère S2, que l'on peut reconstruire en recollant deux disques B2, les hémisphères, le long de leur bord, l'équateur. Si je pars du pôle nord et que j'avance tout droit, je rencontrerai l'équateur, avant de poursuivre sur l'autre hémisphère jusqu'au pôle sud, et continuer le voyage qui me ramènerait jusqu'au pôle nord. Bref, la 3-sphère, c'est deux boules dont les bords ont été identifiées.
Une autre façon de se représenter la 3-sphère, c'est de généraliser la façon dont les platistes se représentent la Terre, sous la forme d'un disque bordé par l'Antarctique. Pour un topologiste, cette représentation est bien celle de la 2-sphère Terre, mais il faut convenir que le cercle qui sert de bord ne représente qu'un seul et unique point, le pôle sud. La sphère S2, c'est donc un disque B2 où tous les points du bord sont identifiés en un seul. En généralisant, on peut dire que la 3-sphère, c'est une boule où tous les points de la surface sont en fait un seul et même point, un pôle. Bref, il y a plein de façon de se représenter cette variété de dimension 3 qu'est la 3-sphère.
On a donc à présent une collection non exhaustive de 3-variétés, et on va essayer de l'élaguer un peu. Déjà, débarassons nous des variétés à bord, et ne gardons que les variétés compactes, celle dont le volume est fini. Il nous en reste encore pas mal, mais la 3-sphère diffère des autres, puisque c'est la seule qui est simplement connexe, c'est à dire que si un élastique se trouve à l'intérieur d'une 3-sphère, il sera toujours possible de le déformer pour le ramener en un unique point. Dans un hyper tore, si l'élastique est tendu entre deux faces identifiées du cube univers, il sera impossible de le réduire en un seul point. Finalement, de toute ma collection de variétés de dimension 3 sans bord et compactes, seule la 3-sphère est simplement connexe. Mais est-ce vraiment la seule, ou on a simplement mal cherché ? Il a fallu 100 ans pour le prouver, parce que c'est ça, l'objet de la véritable conjecture de Poincaré : la 3-sphère est la seule variété de dimension 3 sans bord, compacte et simplement connexe.
D'ailleurs, pourquoi s'intéresse-t-on autant aux variétés simplement connexes ? En fait, on peut voir les variétés simplement connexe comme des briques de bases des autres variétés : si une variété est non simplement connexe, on pourra la couper en des morceaux plus petits. Il est donc primordial de bien comprendre lesquelles sont simplement connexes.
Entre 1904, le moment où la question est posée par Henri Poincaré et 2003, celui où Grigori Perelman dépose en ligne les pdfs de sa démonstration, des générations de mathématiciens s'étaient penchés sur la question. D'abord, dans les années 60, en se débarrassant de la généralisation aux dimensions supérieures à 5, puis dans les années 80 à la variante en 4D. Toujours dans les années 80, Richard Hamilton trouve un angle d'attaque à la conjecture de Poincaré : il s'agit de gonfler la variété 3D pour une faire une hypersphère de la même façon que gonfler un ballon de baudruche le transforme en sphère. Ce gonfleur, c'est le flot de Ricci, et il a fallu attendre 2003 pour que Perelman étudie minutieusement les cas qui ferait éclater le ballon au lieu d'obtenir une hypersphère. Les outils qu'il venait de mettre au point étaient si novateurs et subtils qu'il fallut à la communauté mathématique quelques années supplémentaires avant de confirmer que sa démonstration était bien correcte. S'en sont suivies de nombreuses distinctions, comme la médaille Fields en 2006, ou le prix du millénaire et son millions de dollars en 2010. Des récompenses qu'il refusera, avant de claquer la porte des mathématiques académiques. Les dernières nouvelles que l'on a eu de lui remontent à 2010. Il cueillait des champignons.
Un biopic hollywoodien pour mettre en lumière trois mathématiciennes noires de la NASA, c'est une excellente idée, mais il faut mettre des mathématiques dedans pour être crédible. L'est-ce ?... Voici un nouvel épisode du Chouxrom' Ciné Club.
Script + Commentaires
Je suis la toute première femme noire à avoir décroché un diplôme au cycle supérieur à l’Université de Virginie. Alors oui, ce sont des femmes qui font ce travail à la NASA, Mr Johnson, et ce n’est pas parce que nous portons des jupes, c’est parce que nous portons des lunettes. Bonne journée.
Au ChouxRom’ Ciné Club, on regarde des films de maths. Il y en a des bons, des moins bons, d’autres franchement horribles, et parfois, on tombe sur des perles rares.
Aujourd’hui, parlons de celui qui, parmis tous les films de maths, a obtenu le plus haut succès critique. Voici des figures de l’ombre, le biopic réalisé par Ted Melfi, avec Taraji Henson, Octavia Spencer et Janelle Monáe dans les rôles titres, ainsi que Kevin Costner, Kirsten Dunst et Jim Parsons dans les rôles secondaires. Dans cette adaptation du livre Hidden Figures de Margot Lee Shetterly sorti en 2016, on retrace le parcours de trois mathématiciennes afro-américaine méconnues de la NASA, Katherine Johnson, Dorothy Vaughan et Mary Jackson.
Le film sort en France lors de la journée internationale des droits des femmes le 8 mars 2017, soit en même temps que le dernier volet de la franchise King Kong, ou qu’une comédie française sur le thème du baby phone. Il sera nominé aux oscars du meilleur film, meilleur second rôle masculin et meilleur scénario, mais repartira bredouille face à Moonlight.
Comme d’habitude, je ne dirai rien des qualités cinématographiques des Figures de l’Ombre. C’est un biopic, avec tous les défauts que l’on peut attendre d’un film de ce genre. Cela dit, je vous le recommande vivement si vous ne l’avez pas encore vu, pour son message féministe et antiraciste qui fait un bien fou. Parce que, oui, le film est avant tout un film politique sur la place des femmes et des noirs pendant la guerre froide, et c'est pour ça que le film a été acclamé par la critique. Néanmoins, je vais rester dans l’ordre factuel des choses : que valent les maths dans ce film ?
Les maths sont toujours fiables.
De quoi parle les figures de l’ombre ? Un petit résumé s’impose.
Le film nous conte le destin de trois grandes figures de l’histoire de l’aérospatial américaine : Katherine Johnson, Mary Jackson et Dorothy Vaughan, entre 1961 et 1962 alors que les Etats-Unis appliquent leur politique de ségrégation raciale. Ce sont des femmes, et elles sont noires, autant dire que les portes ne leur seront pas vraiment ouvertes.
Tout d’abord, Dorothy Vaughan. Elle est officieusement superviseure de la section ouest des calculatrices, la section chargée d’effectuer les calculs tant que l’informatique n’existe pas encore, au détail près que celle-ci est réservée aux mathématiciennes noires. Elle cherchera à devenir officiellement superviseure, malgré les refus de sa hiérarchie incarnée par Vivane Mitchell, et devra se battre contre l’arrivée de l’informatique qui menace son travail.
Ensuite, Mary Jackson, qui travaille comme calculatrice dans la section de Vaughan. Elle est invitée à assister l’ingénieur Karl Zielinski sur un projet dans une soufflerie, qui lui conseille de suivre les cours pour devenir elle aussi ingénieure, et ça, malgré les lois qui empêchent les femmes noires d’obtenir un tel diplôme.
Enfin, Katherine Goble, qui deviendra Katherine Johnson au cours du film, est aussi calculatrice dans la section de Vaughan. Elle rejoindra très vite le groupe de travail spatial, sous les ordres de Al Harrison et la supervision de Paul Stafford, dans lequel elle devra faire ses preuves, notamment durant la mission Mercury afin d’envoyer pour la première fois un américain en orbite, John Glenn.
L’histoire racontée par le film est basée sur une histoire vraie, puisque, spoiler, Dorothy Vaughan deviendra la première femme noire à être superviseure à la NASA, Mary Jackson la première femme noire ingénieure à la NASA, et Katherine Johnson assurera avec succès la vérification des calculs de trajectoires pour la mission Mercury. Le livre de Shetterly parle aussi de la mathématicienne et ingénieure Christine Darden, première afro-américaine à décrocher un poste de direction à la NASA, mais elle restera une figure de l’ombre des Figures de l’Ombre.
Avant de parler des mathématiques du film, j’aimerais m’arrêter quelques instant sur le côté basé sur des faits réels. Le réalisateur a pris quelques libertés par rapport à la réalité. Enfin, a pris beaucoup de liberté. Déjà, la moitié des personnages du film ont été créé de toutes pièces. Bien sûr, Katherine Johnson, Mary Jackson et Dorothy Vaughan ont bel et bien existé, bien qu’elles n’aient probablement jamais travaillé ensemble. Le personnage de Al Harrisson, occupe la fonction de Robert Gilruth, chef du groupe de travail spatial à partir de 1958. Karl Ziellinski, mentor de Mary Jackson dans le film, est inspiré très largement de Kazimierz Czarnecki, son mentor dans la réalité. Enfin, Paul Stafford et Viviane Mitchell n’ont jamais existés, ils sont plutôt un patchwork des membres de la NASA de l’époque, l’un représentant le sexisme ambiant, et l’autre le racisme. Sans doute cela faisait mauvais genre de faire incarner ces valeurs par des personnages ayant réellement existé.
L’autre point important à rappeler pour ne pas confondre ce film avec un documentaire est dans la chronologie des faits. L’histoire se déroule entre 1961 et 1962, pourtant 80% de ce qui est montré à l’écran ne s’est pas vraiment passé durant ces deux années. Ainsi, Dorothy Vaughan devient officiellement superviseure de l’unité de calcul de la zone ouest en 1949, soit 12 ans avant les évènements du film. Elle devient ainsi la première afro-américaine, et l’une des premières femmes à obtenir cette fonction. D’ailleurs, en 1949, la NASA ne s’appelait pas encore NASA mais NACA, puisqu’il n’était pas encore question de spatial. Elle rejoindra le département informatique en 1958, soit 4 ans avant ce qui est présenté dans le film. Mary Jackson, quant à elle, a bien travaillé dans le département de Vaughan, mais entre 1951 et 1953, avant de collaborer avec Czarnecki. Elle sera officiellement ingénieure à partir de 1958. Enfin, Katherine Goble travaille dans l’unité de Vaughan à partir de 1952, et rejoindra le groupe de travail spatial à partir de 1958. D’ailleurs, elle se marie et prend officiellement le nom de Katherine Johnson en 1957, pas en 1962.
Le premier vol orbital habité s’est bien déroulé en 1962, et John Glenn a bien demandé à ce que ce soit Johnson personnellement qui s’assure de vérifier manuellement les calculs. Cependant, elle n’a pas fait ce travail en quelques heures comme on le voit à l’écran, mais plutôt en quelques jours. Même s’il est vrai que les calculatrices ne signaient pas leur rapports, Katherine Johnson signait de son nom les siens bien avant cette mission.
Le dernier point un peu plus contestable, c’est cette histoires de toilettes réservées aux personnel noir. Elles ont parfaitement existé avant 1958, mais en réalité, Katherine Johnson n’a jamais eu à en souffrir dans le cadre de son travail, puisqu’elle utilisait sans sourciller celles réservées aux blancs. En fait, celle qui devait faire des aller-retour entre les différents bâtiments n’est pas Katherine Johnson mais plutôt Mary Jackson.
Bref, beaucoup de raccourcis ont été faits, ce qui est dommage mais compréhensible quand on cherche à résumer plusieurs décennies en un film de deux heures.
Un seul consultant mathématique apparait au générique, il s’agit de Rudy Horne, mathématicien et professeur au Morehouse College, à Atlanta. On lui doit quelques dialogues technique entendu dans le film, notamment cette histoire de méthode d’Euler sur lequel je reviendrai. Bien que ce n’est pas lui qui a écrit les équation visibles sur les très nombreux tableaux dans le film, il a été chargé de vérifier qu’elles étaient bien raccord avec ce qui se faisait à la NASA dans les années 50 et 60. Taraji Henson, qui joue Katherine Johnson, rédige quelques équations à l’écran. L’une des tâches de Horne a en effet été de lui enseigner les rudiments des mathématiques afin de pouvoir lire, écrire et comprendre les calculs qu’elle sera amenés à produire. Rudy Horne ne fait aucun caméo dans le film, mais on peut malgré tout repérer son écriture dans l’une des premières scènes du film.
Parlons justement de cette scène. On y rencontre Katherine alors âgée de 8 ans, dans une classe d’élèves visiblement plus vieux. Son professeur lui demande de venir résoudre une équation au tableau. Il s’agit d’une équation produit de deux équations du second degré, le genre que l’on retrouverait en France à un niveau de première, soit vers à peu près 16 ans.. Katherine résout l’équation en la factorisant, la méthode est calculatoire mais tout à fait classique, d’autant que la rédaction présentée est correcte, et la justification orale est tout à fait juste. Bref, la scène est vraisemblable, et si l’idée était de montrer que Katherine est une élève surdouée, la mission est validée.
Ce n’est pas le seul tableau que l’on croise. On compte dans le film plus d’une vingtaine de scènes où l’on peut voir des équations ou des calculs en arrière plan. Ça donne, si j’ai bien compté, plus de 40 tableaux noirs visibles à l’écran, autant dire tout de suite que je ne vais pas essayer de comprendre ce que tous veulent vraiment dire, d’autant que la plupart sont complètement illisibles. En tout cas, et contrairement à d’autres films, ce que l’on peut lire sur les tableau ne semble pas être un assemblage de symboles dénué de sens. Regardons tout de même un peu plus attentivement les deux tableaux qui mettront Katherine sur les devants de la scène.
Le premier, c’est celui que Katherine écrit dans l’indifférence générale sur le grand tableau de la salle de travail. À ce moment du film, elle travaille sur le projet Mercury, dont l’objectif est d’envoyer un homme américain dans un premier temps dans l’espace, puis à terme en orbite. La mission Mercury-Redstone est celle qui enverra Alan Shephard dans l’espace. Alors que son travail était de faire une vérification superflue de calculs pour la fusée Redstone à partir de documents censurés, elle décide de faire autre chose. Un bon gros calcul qui semble particulièrement fascinant aux yeux de ses collègues. Sur la partie haute du tableau, on peut lire des données de la fusée Redstone, données qui disparaissent entre le moment où elle écrit et celui où elle a finit d’écrire, merci Michel. Sur la partie basse, il y a l’énorme calcul. Que raconte-t-il exactement ? Eh bien, c’est difficile à dire puisque le film ne nous donne pas vraiment de contexte. Il est seulement dit que cette formule implique que la fusée Redstone ne peut pas soutenir un vol orbital. Bref, détaillons un peu la formule en question. J’espère que les physiciens corrigeront les approximations que je m’apprête à dire. Nous avons un calcul dans lequel apparaissent 5 constantes : m qui est une masse, v une vitesse, T qui semble être la poussée d’une fusée et k un coefficient de frottement. Le nombre 0.00981 qui apparait dans les calculs est la valeur de l’accélération de la pesanteur. On a donc la formule y = m/2k ln(mg+kv² / mg) - m/2k ln(T-mg-kv² / T-mg). La partie gauche du calcul correspond à la hauteur maximale atteinte par un projectile de masse m lancée vers le haut à une vitesse initiale v, et soumise à des frottements proportionnels au carré de la vitesse. Pour le membre de droite, je n’ai pas réussi à déterminer son sens, mais la formule étant homogène, je suis prêt à parier qu’elle a bien un sens.
Après un peu plus de recherches (merci Brusicor), cette partie de la formule correspond par la hauteur atteinte par la fusée durant la première phase de son ascension, quand elle a encore du carburant à bruler pour augmenter sa vitesse.
Ce que l’on peut facilement faire, par contre, c’est vérifier que le calcul donne bien 3059 km. Malheureusement, ce n’est pas l’avis de ma calculatrice. Bref. Cependant, le calcul de Katherine donne le bon ordre de grandeur, puisqu'elle trouve 3059 au lieu de 3133. L'erreur n'est que d'un oeu plus de 2%, ce qui est correct vu la complexité du calcul. En fait, on ne demande pas à une calcculatrice humaine de faire des calculs exacts, un résultat comme celui qu'elle a trouvé est suffisant. Il est cependant dommage que le résultat écrit au tableau ait autant de chiffres significatifs.
Un point intéressant pour comprendre la scène, c’est la valeur des constantes. Ce qui pèse 118 tonnes, ce n’est pas la fusée Redstone sur lequel devrait travailler Katherine Gobble, mais la fusée Atlas, celle qui enverra John Glenn en orbite l’année suivante. L’utilisation de la fusée Atlas est classifiée top secret pour Katherine, d’où la surprise de l’ensemble de ses collègues, et la mise au point face à sa hiérarchie dans la scène qui suivra. Bref, même si je ne comprend pas complètement l’équation, et que le calcul n’est pas tout à fait juste ce qui est logique pour un calcul sensé être fait de tête, je valide cette scène.
L’autre scène importante qui voit Katherine prendre la craie est celle de la réunion du Pentagone. L’ordre du jour est de préparer la trajectoire de John Glenn et de sa capsule Friendship 7, dans le cadre de la mission Mercury-Atlas 6. Après s’être battue pour pouvoir assister à cette réunion, ce qui est historiquement correct, on lui demande de calculer les coordonnées de la zone d'amerrissage de la capsule. Elle s'exécute, devant le regard incrédule de l’assemblée composée d’hommes blancs. Je passe sur les faux raccords qui laissent imaginer combien de fois Taraji Henson a dû écrire tout ça. Déjà, on a les données, 2990 miles, soit la distance entre la désorbitation et le point d'atterrissage et 17 544 miles à l’heure, soit la vitesse initiale, convertie correctement en pieds par secondes. De quelle vitesse initiale on parle, la question est ouverte.
Le calcul suivant, c’est une conversion en radian de l’angle de descente, de 46.56°. Là encore, pas d’erreurs de calculs.
La formule qui suit, R = V² sin(2y) /g, c’est la formule qui donne la portée d’un projectile lancé depuis le sol à une vitesse v et un angle y. Voir le commentaire de PIXELL57 pour une démonstration de ccette formule. Et c’est là que je ne comprends pas pourquoi cette formule est utilisée, puisque je croyais que quand une capsule quitte son orbite, elle n’est pas au niveau du sol, mais un peu plus haut dans l’espace. Je me trompe peut-être, mais je crois que cette formule n’a pas sa place dans une réunion sérieuse au Pentagone. D’autant que Katherine annonce un résultat de 20 530 372 pieds, ce que ma calculatrice ne confirme pas. Elle trouve 20 530 372 au lieu de 19 959 847, soit une erreur de moins de 3%. Le calcul est donc correct Sa conversion en miles est d’ailleurs elle aussi incorrecte. Elle trouve 2990 au lieu de 3888. L'erreur est de 30%, ce qui n'est pas justifiable. Je commence à douter de ses compétences en calcul, en fait. Cela dit, l’assemblée semble conquise, ces calculs faux ont fait le job. Notons que dans cette scène, les calculs sont fait en utilisant les unités impériales (pieds, miles, etc.), alors que dans la scène précédente, les calculs sont faits en unité SI. Mon hypothèse : la scène précédente se pase au centre de calcul spatiel, le public de Katherine est un public de scientifiques, alors que cette scène se passe au pentagone, le public est militaire..
Vos calculs me plaisent.
Enfin, terminons par l’une des scènes clés du film, lorsque le groupe de travail spatial est confrontés à un problème de calcul de trajectoire, toujours dans le cadre de la mission Marcury-Atlas 6. Pour revenir sur la terre, la capsule doit passer d’une trajectoire elliptique, celle de l’astronaute en orbite autour de la Terre, à une trajectoire parabolique. Les schémas sur le tableau sont d’ailleurs raccord avec la question, bien que les équations me sont tout à fait incompréhensible. La question est de savoir à quel moment précis il faut ralentir la capsule pour basculer d’une trajectoire à l’autre, ce qu’ils appellent le point de Go / No Go.
Katherine Goble a alors une idée brillante : il faut utiliser la méthode d’Euler.
La méthode d’Euler ? Ouais. Mais c’est archaïque. Mais ça fonctionne ! Ça fonctionne numériquement !
C’est très ancien, mais c’est très efficace. Pour le côté ancien, on est d’accord, puisque la méthode d’Euler a été mise au point par Leonhard Euler en 1768. Pour le côté efficace, là, c’est autre chose. Il faut déjà comprendre ce qu’est cette méthode, et à quoi elle peut servir. Il s’agit d’une méthode numérique, c’est à dire, un marche à suivre qui permet de résoudre un problème mathématique de façon approchée, lorsque les méthodes exactes sont trop longues à mettre en place, ou tout simplement impossible. Plus précisément, la méthode d’Euler permet de résoudre numériquement et de façon approchée des équations différentielles ordinaires, c’est à dire des équations dont l’inconnue n’est pas un nombre, mais une ou plusieurs fonctions. Une équation différentielle fait alors intervenir la fonction, sa dérivée, et éventuellement d’autres dérivées.
Pour essayer de comprendre tout ça, prenons un exemple qui n’a absolument rien à voir avec Katherine Johnson, ni avec la conquête spatiale, ni même avec la physique. Parlons plutôt écologie, et le modèle de Lotka-Volterra, un système d’équations différentielles incontournable utilisé pour la première fois en 1910 par Alfred Lotka pour modéliser des réactions chimiques, puis adapté à la biologie dans les années 20 par Vito Volterra. Il est question de proie, disons des lièvres, et de leurs prédateurs, les lynx. Ces deux espèces se partagent un même milieu, et la question qui trotte dans la tête de tous les bio-mathématiciens et bio-mathématiciennes, c’est de prédire comment vont évoluer ces populations en fonction du temps. L’idée, c’est que plus il y aura de lièvres, plus il y aura de lynx, mais beaucoup de lynx impliquent de moins en moins de lièvres, entrainant la disparition des lynx, entrainant à nouveau la prolifération des lièvres, et ainsi de suite.
Mettons tout ça en équation. Posons lièvre(t) la taille de la population de lièvres en fonction du temps, et lynx(t) celle des lynx. Disons que les populations sont données en milliers d’individus, et l’unité de temps est l’année. Pour poser les équations, on va raisonner en mathématicien, et fixer des conditions simplistes.
La première supposition, c’est que les lièvres ont un accès illimité à de la nourriture. Si on oublie temporairement les prédateurs, la croissance de leur population dépendra donc directement de leur nombre. Traduisons ça en équation. La croissance de la population des lièvres, c’est la dérivée de la fonction lièvre, notée lièvre’(t), ce qui correspond au nombre de nouveaux lièvres par unité de temps. Notre hypothèse, c’est que cette dérivée est proportionnelle au nombre de lièvres. Le coefficient a, c’est ici le taux de reproduction des lièvres, que l’on supposera constant. Remettons maintenant les prédateurs dans l’équation, les seuls qui peuvent diminuer le nombre de lièvre, et ce d’autant plus vite qu’ils seront nombreux. On doit donc retirer à la croissance des lièvres un nombre proportionnel au nombre de lièvres et de lynx. Le coefficient b, c’est le taux de mortalité des lièvres dû aux prédateurs.
Pour ce qui est des lynx, l’étude est équivalente, et on obtient une équation similaire.
On suppose, en mettant temporairement de côté la mort naturelle des lynx, que leur croissance est proportionnelle au nombre de lièvre et de lynx, d'où lynx'(t) = c lièvre(t) lynx(t). Le coefficient c est ici le taux de reproduction des lynx grace aux lièvres. On supposera enfin que les lynx mourront d'autant plus vite qu'ils sont nombreux, il faut donc retirer à la croissance lynx'(t) un nombre proportionnel au nombre lynx. On retire donc d lynx(t). Le coefficient d, c'est le taux de mortalité des lynx.
On obtient donc le système d'équations :
lièvre'(t) = a lièvre(t) - b lièvre(t) lynx(t)
lynx'(t) = c lièvre(t) lynx(t) - d lynx(t)
Le couple d’équations différentielles que l’on obtient, ce sont les équations de Lotka-Volterra, qui modélise l’évolution d’un système proie-prédateur, et ce de façon si simpliste que cela ferait bondir n’importe quel biologiste. Simplifions encore, en fixant les paramètres à des valeurs précises : on va prendre 0.5 pour a et b, et 0.25 pour c et d. On supposera que la population initiale de lièvres compte 1200 individus, et celle des lynx en compte deux fois moins. Ces nombres sont tout à fait arbitraires.
Bref, on a des équations, et il faut les résoudre, c’est à dire, trouver les fonctions lièvres et lynx qui vérifient les deux équations. Le soucis, c’est que ces équations sont impossibles à résoudre de façon exacte, on ne pourra pas trouver d’expression explicites pour les fonctions lièvres et lynx. La théorie des équations différentielles permet quand même de dire des choses intéressantes, notamment que des solutions existent, et que celles-ci sont périodiques, ce qui implique que les population ne dépasseront jamais un certain seuil.
Maintenant que l’on a fait le deuil d’une solution exacte, on va quand même chercher de manière approchée à quoi pourraient ressembler ces fonctions. Pour cela, et c’est là où je voulais en venir, on va utiliser la fameuse méthode d’Euler, historiquement la première méthode numérique qui permet de résoudre une équation différentielle de manière approchée.
L’idée est la suivante : on va se fixer un pas, disons 6 mois pour commencer, et on va faire comme si les dérivées, c’est à dire les vitesse de croissance que l’on calcule avec les équations, ne changeaient que tous les 6 mois. Dans notre exemple, les valeurs initiales des fonctions lièvre et lynx sont 1.2 et 0.6. On peut alors calculer les valeurs initiales des dérivées. Pour lièvre’(0), on trouve 0.24 milliers de lapins par an, et pour lynx’(0), on trouve 0.03 milliers de lynx par ans. Normalement, ces valeurs correspondent à l’évolution des populations uniquement à l’instant 0, mais la méthode d’Euler implique de considérer ces évolutions comme constantes pendant la durée sélectionnée, et c’est en ça qu’il s’agit d’une méthode approchée et non exacte. On va donc supposer que, pendant 6 mois, les lièvres augmentent de 0.24 milliers par ans, et les lynx de 0.03 milliers par ans. On a donc maintenant une valeur approchée du nombre de lièvres et de lynx après 6 mois : 1320 lièvres et 615 lynx. Poursuivons. Les équations différentielles nous permettent à présent de calculer maintenant les dérivées au temps t=0.5, ce qui nous donne le nombre d’animaux après 1 an, un nombre encore plus imprécis que le premier. On peut alors poursuivre les calculs, ce qui nous permet d’obtenir les fonctions recherchées : le nombre de lièvres et de lynx en fonction du temps sur une période de 50 ans.
On constate alors que le modèle correspond assez bien aux observations : le nombre de lièvres et de lynx a un comportement périodique, et les trajectoires des courbes sont similaires, avec un retard d’environ 3 ans. À en croire ces courbes, les populations de lièvres deviendront de plus en plus grandes au fil des années, ce qui est incompatible avec la théorie, leur nombre devrait être bornée. Ces courbes que l’on a obtenu sont grossièrement fausses, et c’est l’un des problèmes de la méthode d’Euler, son instabilité. Le pas de 6 mois que l’on a choisi pour appliquer la méthode est manifestement trop grand. Ce qu l’on peut faire pour résoudre le problème, c’est prendre un pas plus petit, comme un mois ou un jour. Avec un tel pas, la courbe obtenu est plutôt fiable, mais elle a demandé beaucoup trop de calculs. En pratique, pour résoudre numériquement une équation différentielle, on utilise rarement la méthode d’Euler qui possède beaucoup de défauts pour peu de qualités, et on lui préfère ses nombreuses variantes. Bref, Il est assez improbable que la méthode d’Euler soit vraiment utilisée pour faire des calculs précis de trajectoires de fusées.
Heureusement, le film rectifie tout de suite ce problème. Quand on voit Katherine se renseigner dans un livre sur la méthode d’Euler, elle ouvre sur la page détaillant la méthode d’Euler modifiée, et on devine sur la page suivante les bien plus efficaces méthodes de Runge-Kutta. Je suis rassuré, personne ne sera envoyé en orbite avec des calculs utilisant des méthodes numériques pas tout à fait fiables.
J'ai finalement très peu parlé de Mary Jackson ni de Dorothy Vaughan. Pour Mary Jackson, la seule scène où on la voit faire facce à des équations est la scène où elle prend ses cours du soir pour devenir ingénieure. On peut y voir l'équation de Shrodinger, il s'agit donc de physique quantique, sur laquelle je ne peux pas raconter grand chose. Pour ce qui est de Dorothy Vaughan, aucune scène ne la montre en train de faire des maths, mais plutôt de l'informatique. Rien de concret n'est présenté, on la voit simplement lire des livres sur le langage FORTRAN, et manipuler des ordinateurs.
Finalement, malgré les erreurs de calculs et les formules étranges, je ne peux malgré tout pas en vouloir au film. Les formules écrites sur les tableaux ne sont pas faites pour être compréhensibles, et personne de normalement constitué n’a le temps de sortir sa calculatrice pour en vérifier l’exactitude. En revanche, les passages mathématiques qui sont fait pour être compris sont irréprochables, lorsque Katherine Goble explique l’intérêt de la méthode d’Euler ou que Paul Stafford explique le Go/ No Go. De toutes façons, l’objectif de ces scènes, c’est de décrire le travail des mathématiciens et mathématiciennes pendant la course à l’espace, et ça, et bien, c’est parfaitement réussi.
Dans mon dernier post, je dessinais des courbes avec deux épicycloïdes. Mais avec une, c'est mieux. Du coup, j'en ai fait une vidéo.
Script :
En 1953, le physicien Freeman Dyson présente fièrement à Enrico Fermi ses résultats en électronique quantique. Fermi fait la fine bouche, et lui rétorque alors que son modèle comporte bien trop de paramètres inutiles. Comme le disait selon lui John Von Neumann, avec 4 paramètres, je peux faire une bonne approximation d’un éléphant, et avec un cinquième, je peux lui faire bouger la trompe. Autrement dit, avec suffisamment de paramètres arbitraires, on peut dessiner n’importe quoi.
Plus récemment, l’artiste Jagarikin a twitté un gif montrant comment avec une centaine de cercles, on peut dessiner la jeune fille à la perle de Vermeer. Ce n’est pas sans rappeler cette vidéo de Santiago Ginnobili dessinant les traits de Homer Simpson. La clé de tous ces dessins, ce sont les approximation par des séries de Fourier, et j’espère que vous aimez la trigonométrie et les nombres complexes, parce que ça tombe bien, j’ai deux minutes pour en parler.
Prenons un cercle, puis prenons un point tournoyant sur le périmètre de ce cercle, que je vais appeller point n°1. Très bien. Maintenant, prenons un deuxième cercle dont le centre est le point tournoyant, et prenons un autrepoint, que j’appellerai sans surprise point n°2, en rotation sur le pourtour de ce deuxième cercle. Suivons alors la trajectoire suivie par ce point n°2. Cette courbe que l’on découvre alors, avec ses feuilles régulièrement espacée, est ce que l’on appelle une épicycloïde. Historiquement, ces courbes sont apparues pour la première fois en astronomie.
En effet, si on considère que le premier cercle décrit la rotation du Soleil autour de la Terre, et que le deuxième décrit la rotation d’une planète autour du Soleil, alors les épicycloïdes correspondent aux trajectoires des planètes dans un modèle où la Terre serait au centre de l’Univers. Quand l’astronome de l’Antiquité Ptolémée étudiait les mouvement des astres depuis son modèle géocentrique, c’est donc en étudiant des épicycloïdes qu’il est parvenu à calculer par exemple la date de certaines éclipses.
En choisissant les bons rayons et les bonnes vitesses de rotation, on obtient toute une galerie d’épicycloïdes. On peut obtenir la cardioïde, courbe en forme de cœur, la néphroïde, courbe en forme de rein, ou bien la renonculoïde, courbe en forme, comme son nom l’indique, de renoncule. Oui, pour nommer une épicycloïde, on regarde vaguement la forme de la courbe, et on ajoute -oïde à la fin. J’aurais aussi pu évoquer la deltoïde, en forme de la lettre grecque Δ, ou bien l’astroïde, en forme d’astre.
Ne nous arrêtons pas en si bon chemin. Et si, autour du point n°2, on faisait orbiter un point supplémentaire, que l’on pourrait appeler point numéro 3. Cette trajectoire, suivie par ce point n°3 est… particulièrement esthétique ! Officiellement, cette courbe porte toujours le nom d’épicycloïde, mais je préfère parler d’épi-épicycloïde, même si je suis le seul à utiliser cette terminologie.
Bien sûr, j’ai choisi les rayons et les vitesses de rotation pour que le résultat vaille le coup d’œil. Je vous rassure, il est parfaitement possible de trouver des échafaudages de cercles tournoyants qui tracent des épicycloïdes particulièrement laides.
Dès lors, il n’y a plus de raisons de se restreindre sur le nombre de cercles pour tracer mon épi-épicycloïde. Voici donc huit cercles orbitant les uns autour des autres. Qu’obtient-on si on suit la trajectoire du point n°8 ? Eh bien, c’est une épicycloïde remarquable, puisqu’il s'agit d’une éléphantoïde !
Mais comment ce pachyderme a-t-il bien pu se retrouver là ? Pour le comprendre, on va devoir mettre en équation toutes ces épicycloïdes, et c’est là que la trigonométrie va rentrer en jeu. Forcément, ça va être un peu technique, mais je vais essayer de vous prouver que la trigo, ça peut être cool, même si j’espère que pour vous ça ne sera pas trop douloureux.
Reprenons un cercle. Disons, de centre O et de rayon 10, et un point P1 sur ce cercle. En notant t l’angle formé entre le rayon OP1 et l’horizontale, la trigonométrie nous indique que le vecteur OP1, et donc le point P1, ont pour abscisse 10 cos(t), et pour ordonnée 10 sin(t). Maintenant, on ajoute un nouveau cercle centré sur P1, disons de rayon 4. Sur ce cercle, on a un point P2, qui tourne deux fois plus vite que P1. Cela signifie que l’angle formé entre le rayon P1P2 et l’horizontale est deux fois plus grand que le premier angle, et vaut donc 2t. Le vecteur P1P2 a donc pour coordonnées (4 cos(2t), 4 sin(2t)), si bien que le point P2 a pour abscisse 10 cos(t) + 4 cos(2t) et pour ordonnée 10 sin(t) + 4 sin(2t). Bref, on a finalement l’équation paramétrique de l’épicycloïde.
En généralisant la construction, on peut voir que l’équation paramétrique de ces cycloïdes pourront s’écrire sous la forme de somme de fonctions cosinus de différentes fréquences pour les abscisses, et d’une somme de sinus de différentes fréquences pour les ordonnées. Dans cette équation, les nombres réels a correspondent aux rayons des cercles, et les nombres entiers n sont les vitesses de rotations des cercles. Si on connait cette équation, on peut donc retrouver tous les éléments pour construire avec des cercles roulants l’épicycloïde qui nous intéresse.
Mais le problème qui se pose à nous est plutôt le problème opposé. Comment calculer la taille des cercles qui permettent de tracer une épicycloïde que l’on aurait sous le nez ?
Prenons par exemple cette courbe, une superbe handspinneroïde. Comment vais-je pouvoir procéder pour la dessiner façon spirographe ? Une première idée, c’est de chercher une équation paramétrique, c’est à dire l’expression de l’abscisse x et de l’ordonnée y en fonction du temps t que met un point à parcourir la courbe. On prend donc un point, ici en violet, qui suit l’épicycloïde, ce qui nous donne, en bleu, l’abscisse en fonction du temps t, et en rouge, l’ordonnée en fonction du temps t. On va s’intéresser seulement à x(t) pour l’instant.
Puisque mon épicycloïde est une courbe fermée, la fonction x est périodique, d’une période τ=2π. Ça tombe bien, on connaît justement toute une tripotée de fonction pas trop compliquées de période τ=2π. Il y a les fonctions cosinus et la fonction sinus, et toutes leur variante de période τ/2, τ/3, τ/4, etc.
Faisons alors l’hypothèse que x(t) peut s’écrire sous la forme d’une combinaison linéaire de toutes les fonctions de période τ que l’on vient de lister, parce que, après tout, pourquoi pas. Cela veut dire que, a priori, on pourrait écrire x(t) = a₀ + a₁ cos(t) + a₂ cos(2t) + a₃ cos(3t) … + b₁ sin(t) + b₂ sin(2t) + b₃ sin(3t) + …. Je vous passe la théorie qui nous dit que la fonction x est un point dans un espace vectoriel muni d’un produit scalaire où f scalaire g est défini par l’intégrale entre 0 et τ de f(t) g(t) dt, et je passe à la conclusion : si x(t) peut s’écrire sous cette forme que l’on veut, alors les coefficients aₖ et bₖ peuvent être calculés, et ce à l’aide d’intégrales. Ces nombres sont ce que l’on appelle les coefficients de Fourier réels de la fonction x, du nom de Joseph Fourier, qui au début du XIXe siècle a utilisé cette décomposition pour résoudre une histoire d'équation de propagation de chaleur. En fait, il ne s’est pas contenté d’utiliser cette décomposition pour les équations de la chaleur, mais il a montré qu’elles pouvaient s’appliquer à n’importe quelle fonction. À l’époque, tout ça manquait de rigueur, mais la théorie de Fourier venait de naitre, donnant un nouveau champs d’investigation pour des générations de mathématiciens après lui, et je ne parle pas de la floppée d’applications concrètes. Bref, faisons les calculs dans le cas de la courbe qui nous intéresse : pour x(t), on trouve 6 cos t + 1.5 cos 2t + 2 cos 4t + 2.6 sin 2t, et pour y(t), on trouve une équation du même style
Petite déconvenue, puisque ces équations ne correspondent pas vraiment aux équations générale des épicycloïdes que l’on a trouvé tout à l’heure. Déjà, parce que x(t) ne devrait être une somme que de cosinus, et y(t) que de sinus, ce qui n’est pas ici le cas. En jouant un peu avec les mal-aimées formules de trigo, on peut malgré tout se ramener à une forme un peu plus intéressante, avec seulement des cosinus, ou seulement des sinus. On introduit alors une phase à nos fonctions cosinus et sinus. Oui, en fait, j’ai menti tout à l’heure quand j’ai parlé de l’équation paramétrique d’une épicycloïde quelconque, puisqu’il faut aussi prendre en compte la phase de chaque cercle. Je m’explique. J’ai en effet présupposé que lorsque l’angle t est égal à 0, les rayons des cercles étaient tous horizontaux, ce qui n’a aucune raison d’être le cas. On peut supposer, par exemple, que dans la position initiale, le rayon du premier cercle n’est pas horizontal, mais forme un angle de 30° avec l’horizontal. Ce 30°, c’est la phase du premier cercle, et en prenant cela en compte, on obtient une paramétrisation des épicycloïdes un peu plus correcte. Dans ces formules, les coefficients a sont les rayons des cercles, les coefficients θ leur phase, et les coefficients n leur vitesse de rotation.
Il reste malgré tout un autre problème, c’est que les coefficients de x(t) que l’on vient de calculer devraient être égaux à ceux de y(t), ce qui n’est pas vraiment le cas ici. En fait, l’expression de x(t) nous donne les caractéristiques de la construction d’une épicycloïde, et celle de y(t) donne les caractéristiques d’une autre, et celles-ci semblent n’avoir aucun rapport avec la courbe que je cherche à construire. En fait, si. Si je prend l’abscisse du point traceur de la première, et l’ordonnée de la deuxième, on retrouve mon handspinneroïde. C’est pas la construction que l’on espérait, mais on va s’en contenter dans un premier temps.
J’ai donc a priori tout ce qu’il faut pour fabriquer un système de cercles qui me permettrait de dessiner n’importe quelle courbe, comme une toile de maitre à la façon de Jagarikin. Passons donc à un cas pratique. M’est-il possible de trouver deux épicycloïdes qui permettent de tracer une courbe qui ressemblerait à cet éléphant, par exemple ? Bien sûr, il suffit de calculer les intégrales de tout à l’heure. Mais si je veux faire ça, j’ai besoin d’avoir les coordonnées des points de la silhouette, afin d’obtenir les fonctions x et y. Pour les déterminer, un petit logiciel de dessin vectoriel fera l’affaire, et pour le calcul des coefficients, une approximation des intégrales par la méthode des rectangles sera suffisante. Ça demande beaucoup de calculs, et il existe des algorithmes qui permettent de les faire assez rapidement, mais je vais me contenter ici des formules les plus simples à appliquer. Bref, la théorie de Fourier me donne l’équation paramétrique de la courbe, et quelques manipulations supplémentaires permettent de confirmer qu’avec les bons échafaudages de cercles tournicotant, on peut dessiner ce que l’on veut, la preuve avec ce bon pachyderme. À ce propos, le moteur de calcul Wolfram alpha possède dans sa base de données un grand nombre d’équation de courbes, notamment un nombre impressionnant pokémonoïdes, dont les équation paramétriques pleines de fonctions trigonométriques permettent d’affirmer que la théorie de Fourier n’est pas bien loin.
Ce qui est également sympa, c’est que l’on peut calculer plus ou moins de coefficients, suivant la précision que l’on souhaite obtenir. L’éléphant ici présent est construit à partir de deux épicycloïdes à 25 cercles, mais on peut en réduire le nombre, pour calculer l’essence de ce qu’est un éléphant. Et ça, c’est quand même cool !
Mais il reste un petit gout de pas terminé. Avoir deux ensembles de cercles qui tracent un dessins, c’est bien, mais moi, je n’en voulais qu’un seul ! On a du se fourvoyer quelque part. Revenons au moment où nous cherchions l’équation d’une épicycloïde. Il y a une autre façon de décrire par une équation la position de leurs points. Plutôt que d’utiliser les coordonnées cartésiennes, on va considérer que l’on est dans le plan complexe. On reprend un cercle de rayon 10, et un point P1 qui gravite sur ce cercle. En notant t l’angle formé entre OP1 et l’axe horizontal, on peut dire que P1 a pour affixe complexe 10exp(it). On peut aussi prendre en compte la phase du cercle, en multipliant par exp(iθ), où θ est la phase du cercle. Si, à présent, on ajoute un point P2 qui tourne sur un cercle de rayon 4 autour de P1 et deux fois plus vite, on peut voir que le point aura pour affixe 10 exp(it) + 4 exp(2it).
En poursuivant la construction, on peut obtenir une paramétrisation des points des épicycloïdes, sous la forme d’une somme d’exponentielles complexes. Cette somme, c’est ce que l’on appelle la décomposition en série de Fourier complexe de l’équation de la courbe. Les coefficients entiers relatifs n indiquent les vitesses de rotation des cercles, et les coefficients complexes a nous fournissent le rayon des cercles (le module de a), ainsi que leur phase (l'argument de a).
Je vous passe une nouvelle fois les détails, mais il est possible, étant donné un dessin quelconque, de calculer ces coefficients à l’aide d’un bon calcul d’intégrale. Passons plutôt à la pratique. Je prends un éléphant, j’échantillonne son profil, je calcule les coefficients de Fourier, j’en déduis les caractéristiques des cercles, je trace l’épicycloïde qui en résulte, et paf, j’obtiens un éléphant !
Alors, bon, c’est une version approximative du dessin original, mais il y a de bonnes raisons à cela. Déjà, j’ai échantillonné la silhouette de l’éléphant avec à peine 250 points, ce qui est beaucoup, mais malgré tout pas énorme vu sa complexité. Mais ce qui rend mon dessin approximatif, c’est plutôt le nombre de cercles utilisés. Vu que mon éléphant n’est pas vraiment une épicycloïde, il faudrait calculer un nombre infini de coefficients pour avoir la précision maximale. En pratique, c’est bien sûr impossible, donc j’ai du me limiter. Avec 50 cercles, la précision est plutôt bonne, et avec 80 je considère que la courbe est parfaite pour le dessin que je souhaitais obtenir. Pour une meilleure précision, il suffit donc d’augmenter mon nombre de cercles, c’est à dire, calculer davantage de coefficients de Fourier. Dans la vidéo où l’épicycloïde trace les traits de Homer Simpson, l’auteur a utilisé pas moins de 1000 cercles. Forcément, la précision est incroyable !
Bref, grâce aux coefficients de Fourier, il m’a été possible de très bien résumer mon éléphant en utilisant seulement 80 paramètres complexes, là où un dessin point par point avec des segments aurait demandé au moins 410 points. On peut d’ailleurs réduire le nombre de cercle en supprimant les plus petits d’entres eux, et sans trop perdre en précision dans le tracé. C’est une excellente manière de compresser des données. C’est d’ailleurs pour cette raison que la théorie de Fourier entre autres est utilisé dans la compression de fichiers, notamment des photos avec le format jpeg, ou de la musique avec le format mp3. Mais ce n’est pas là dessus que je veux insister, il y a en effet trop de choses à raconter sur les transformations de Fourier pour être exhaustif dans une vidéo qui ne cherche qu’à dessiner de mignons éléphants.
La véritable question, c’est plutôt, comment dessiner notre nouvel animal préféré comme Fermi et Von Numann prétendent être capable de le faire, avec pas plus de 4 paramètres ? En 1975, le chimiste James Wei a pris le pari de réaliser cette prouesse, mais a lamentablement échoué, puisque son dessin d’éléphant demandait tout de même 30 paramètres. Il a fallu attendre 2009, et pas moins d’une équipe de trois biologistes pour obtenir le plus léger des éléphants. Grâce à la technique de décomposition de Fourier en somme de sinus et de cosinus, Mayer, Khairy et Howard ont pu dessiner cette courbe. Un peu cartoon, oui, mais il s’agit bien d’un éléphant, surtout si on rajoute un point aux coordonnées (20,20). Leur équation fait apparaitre 8 paramètres réels, ce qu’une pirouette mathématique ramène à seulement 4 paramètres complexes. Von Neumann avait raison : avec seulement 4 paramètres on peut approximer la silhouette d’un éléphant ! Un cinquième paramètre est utilisé pour faire bouger la trompe, ou, plus précisément, pour indiquer l’abscisse du point d’attache au corps ; le détail des mouvements de cette trompe n’est cependant pas explicité dans le papier. Notons également que c’est ce cinquième paramètre qui code la position de l’œil. Bref, pari réussi.
Bien sûr, cette histoire d’éléphant de Fermi et Von Neumann est anecdotique, et le papier de Wei, comme celui de Mayer, Khairy et Howard, ont été rédigés au second degré. Il n’empêche que cette blague de théoricien a traversé les âges pour une bonne raison. Si on peut retrouver l’allure d’un éléphant avec seulement 4 paramètres, cela veut dire qu’il faut toujours faire très attention à la façon dont on détermine l’ajustement d’une série statistique. Une régression affine demande deux paramètres, une régression parabolique en demande trois, et il semble qu’une régression pachydermique en demande 4. C’est ce que l’on appelle le problème de l’overfitting, maltraduit en français par surapprentissage, et je vous renvois aux vidéos de Lê de la chaine Science 4 all pour détailler toutes ces notions. En attendant, je vous laisse dessiner n’importe quoi avec des épicycloïdes !
Depuis quelques jours circule une très chouette animation montrant des épicycloïdes dessiner la jeune fille à la perle de Johannes Vermeer. Parce que, oui, les épicycloïdes dessinent très bien, et ça ressemble à ceci :
Quand on voit cette animation, on est en droit de ce demander par quelle sorcellerie une telle prouesse est possible ? Pour le savoir, il va falloir fouiller du côté des épicycloïdes et de la théorie de Fourier.
Les (épi)cycloïdes On appelle épicycloïde la courbe que l'on obtient en suivant la trajectoire d'un point situé situé sur le périmètre d'un cercle roulant sur un autre cercle; L'exemple le plus simple d'épicycloïde est la cardioide, obtenue en regardant un disque rouler sur le périmètre d'un disque de même rayon.
Je voulais sortir cet article pour la saint-Valentin, mais c'est raté
Pour simplifier nos équations, on va considérer un autre type d'épicyloïdes (qui ne mériteraient pas de porter ce nom, mais on va faire avec). Au lieu de faire rouler un cercle sur le périmètre d'un autre, on va plutôt faire rouler le centre du cercle sur le périmètre d'un autre. En prenant, par exemple, un cercle porteur de rayon 4, et un cercle porté de rayon 2, et on faisant tourner ce deuxième cercle deux fois plus vite que le premier, on obtient... à nouveau une cardioïde :
Une bien jolie cardioïde
On peut bien sûr faire varier les paramètres (taille des cercles et vitesse de rotation), ce qui donne toute une collections d'épicycloïdes :
De bien jolies épicycloïdes
Mais rien ne nous empêche de faire porter au cercle tournoyant un nouveau cercle tournant, ce qui permet d'obtenir des épi-épi-cycloïdes. Avec trois cercles, il y a donc de nombreux paramètres à prendre en compte, ce qui nous donne toute une galerie de courbes possibles. En prenant, par exemple, des cercles de rayon 5, 2.5 et 1.5, et des vitesses de rotations de respectivement 1, 2 et 3, on obtient la courbe suivante :
Une bien jolie épi-épicycloïde
Une excellente question à se poser, c'est celle de l'équation des courbes que l'on obtient. Pour comprendre l'idée, reprenons la situation précédente. On a donc les rayons de rayons respectifs 5, 2.5 et 1.5, et ces rayons forment des angles mesurant respectivement α, 2α et 3α par rapport à l'horizontale (on suppose ici que les phases sont toutes de 0, c'est à dire que avant de se mettre à tourner, les rayons colorés sont tous alignés). On peut alors déterminer les coordonnées du point traceur M en fonction de α :
Les coordonnées du point M peuvent s'exprimer à l'aide de l'angle α entre l'horizontale et le rayon du cerlce porteur
on peut alors voir, sur le schéma, que l'abscisse de M est donné par xM(α) = 5 cos(α) + 2.5 cos(2α) + 1.5 cos(3α)
de la même manière, son ordonnée est donné par yM(α)=5 sin(α) + 2.5 sin(2α) + 1.5 sin(3α)
De manière générale, si on a N cercles, de rayons r1, r2, ... rN, et qu'ils tournent à des vitesse de respectivement k1, k2, ..., kN, on obtient pour le point M les coordonnées :
Tout ça, c'est lorsque les cercles ont toutes la même phase, de 0. Ce que je vais appeler la phase, c'est la direction de référence sur les cercles par rapport à laquelle on calcule l'angle α. En choisissant une autre phase β pour par exemple le premier des trois cercles, on obtient une épicycloïde radicalement différente :
De manière générale, si on a N cercles, de rayons r1, r2, ...,rN, de phase β1, β2, ..., βN, et qu'ils tournent à des vitesse de respectivement k1, k2, ..., kN,, on obtient pour le point M les coordonnées :
Mettons ces équations dans un coin de notre tête, et parlons à présent de tout autre chose chose
Décomposition d'une courbe paramétrique à l'aide de ses coefficients de Fourier Avertissement : je n'y comprends pas grand chose en théorie de Fourier, j'espère ne pas dire de contre-vérités dans les paragraphes qui vont suivre. Si c'est le cas, dites-le moi très vite.
Prenons un joli dessin. Disons, la silhouette de la France dessinnée à main levée sur Geogebra, mais vous pouvez prendre ce que vous voulez du moment qu'il s'agit d'une courbe refermée sur elle-même.
La France métropolitaine continentale (vue d'artiste)
Comment trouver une équation paramétrique de cette courbe qui soit suffisamment proche de la courbe originale ? Il nous faut, en fonction de α ∈ [0;2π], les coordonnées (x(α);y(α)) des points de la courbe. Une méthode pas trop compliquée à mettre en place est de déterminer la décomposition sous la forme d'un polynôme trigonométrique des fonctions x et y, c'est à dire écrire x et y sous la forme :
Comment s'y prendre pour déterminer tous ces coefficients ? Le plus simple, c'est d'échantillonner le dessin que j'ai fait au-dessus. En l'occurence, celui-ci est constitué de M=578 points, que l'on va soigneusement numéroter de 1 à 578 :
Comptez bien, il y a 578 points
J'ai donc maintenant deux suites (xj) et (yj), et ce sont celles-ci qu'il faut approcher par les bonnes fonctions α↦x(α) et α↦y(α) :
Les 578 abscisses en bleus, et les 578 ordonnées en rouge
En l'occurence, il se trouve que l'on peut calculer les coefficients a0, a1, .. aN et b1, b2, ..., bN de la fonction
à l'aide d'une transformée de Fourier discrète, ce qui ressemble, sauf erreur de ma part, à :
a0 = 1/M Σj xj
ak = 2/M Σj xj cos(k 2π/M j)
bk = 2/M Σj xj sin(k 2π/M j)
et de même pour les coefficients a'0, a'1, .. a'N et b'1, b'2, ..., b'N de pour la fonction yN.
En faisant tous ces calculs avec N=10, on détermine les équations de deux fonctions trigonométriques ayant l'allure recherchée :
Courbes approchant pas trop mal l'échantillonage réalisé au-dessus.
Il n'y a plus qu'à tracer la courbe paramétrée par (xN(α);yN(α)), et paf, on obtient les grandes lignes de notre carte de France !
La France d'ordre N=10
Bien sûr, puisque l'on a pris des des fonctions trigonométriques de périodes d'au plus N=10, la courbe obtenue est relativement sommaire. On pourrait avoir un peu plus de détails en prenant une meilleure valeur de N, par exemple avec N=20 :
La France d'ordre N=20, bien plus pécise
Le lien entre tout ça On a donc, d'un côté, des épicycloides, d'équations paramétriques :
On peut en fait transformer l'écriture de ces derniers polynômes, en remarquant que a cos(kα) + b sin(α) = r cos(kα + β) avec r et β tels que a - ib = r e i β
Bref, l'équation paramétrique du joli dessin que l'on cherche à recréer s'écrit sous la forme
la première, au-dessus de notre dessin, constitués de N cercles de rayons r1, r2, ..., rN, de phase β1, β2, ...,βN et de périodes 1, 2, ..., N, dont l'abscisse du point externe sera l'abscisse des points du dessin
la deuxième, à gauche, constitués de N cercles de rayons r'1, r'2, ..., r'N, de phase β'1, β'2, ...,β'N et de périodes 1, 2, ..., N, dont l'abscisse du point externe sera l'ordonnée des points du dessin (pour ce faire, une petite symétrie est nécéssaire).









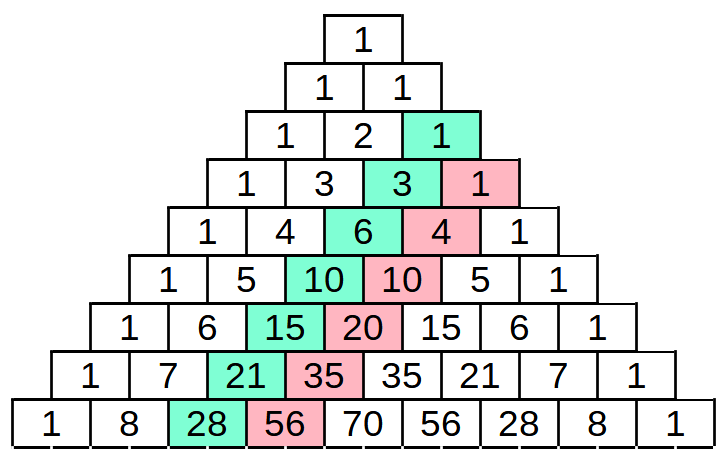
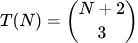











































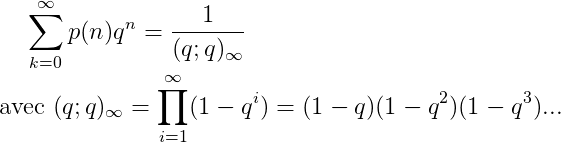
 Nombre de propriétés de chaque années répertoriées dans l'OEIS
Nombre de propriétés de chaque années répertoriées dans l'OEIS






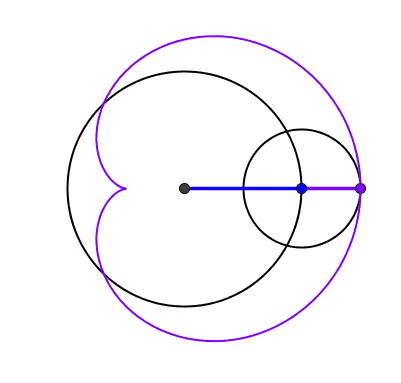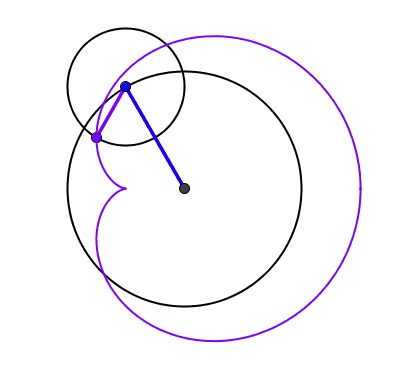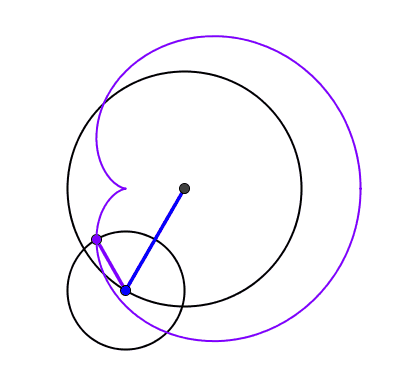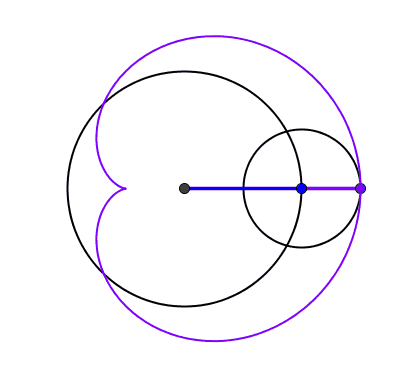
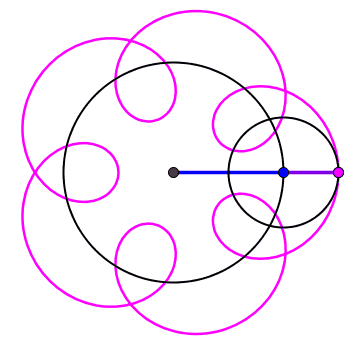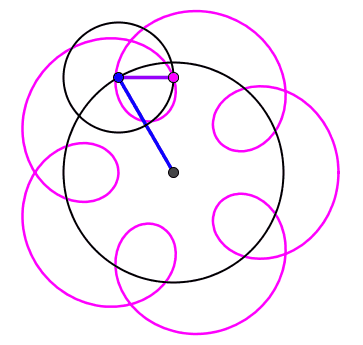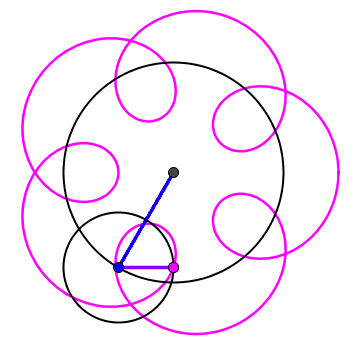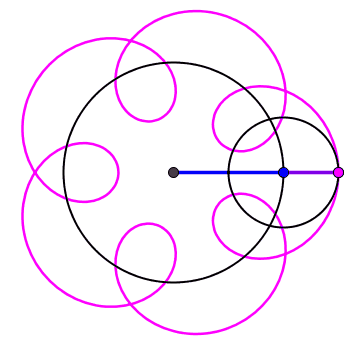

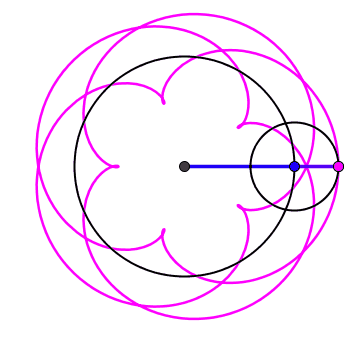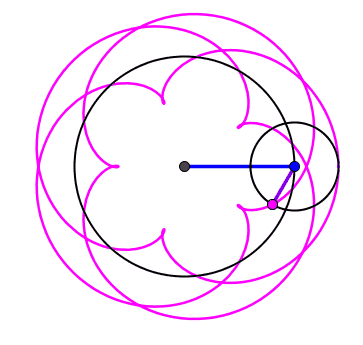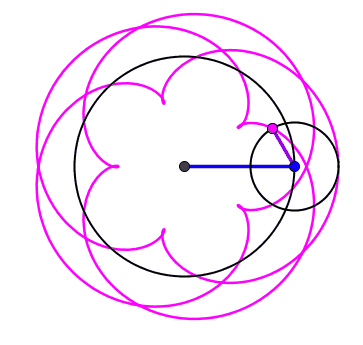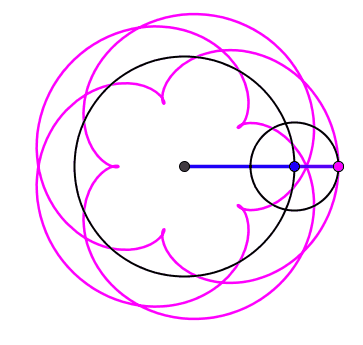
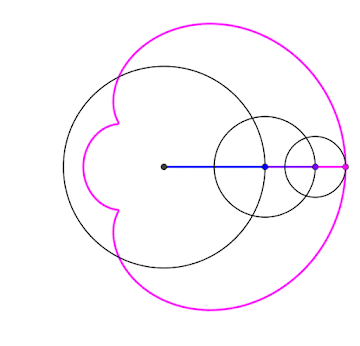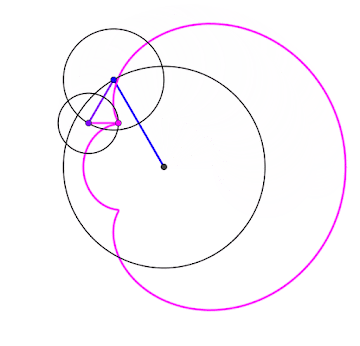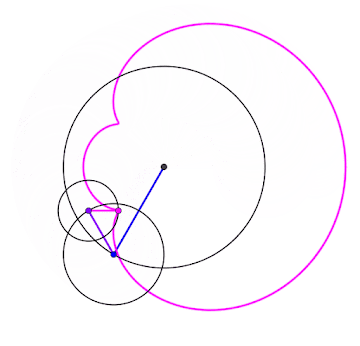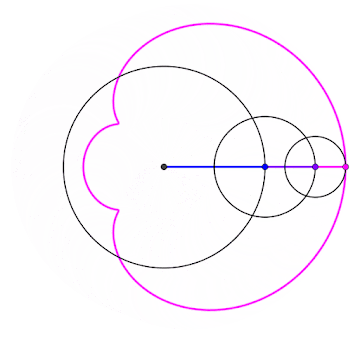









{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}